前端实现录音有两种方式,一种是使用MediaRecorder,另一种是使用WebRTC的getUserMedia结合AudioContext,MediaRecorder出现得比较早,只不过Safari/Edge等浏览器一直没有实现,所以兼容性不是很好,而WebRTC已经得到了所有主流浏览器的支持,如Safari 11起就支持了。所以我们用WebRTC的方式进行录制。
利用AudioContext播放声音的使用,我已经在《Chrome 66禁止声音自动播放之后》做过介绍,本篇我们会继续用到AudioContext的API.
为实现录音功能,我们先从播放本地文件音乐说起,因为有些API是通用的。
1. 播放本地音频文件实现
播放音频可以使用audio标签,也可以使用AudioContext,audio标签需要一个url,它可以是一个远程的http协议的url,也可以是一个本地的blob协议的url,怎么创建一个本地的url呢?
使用以下html做为说明:
|
1 2 |
<input type="file" onchange="playMusic.call(this)" class="select-file"> <audio class="audio-node" autoplay></audio> |
提供一个file input上传控件让用户选择本地的文件和一个audio标签准备来播放。当用户选择文件后会触发onchange事件,在onchange回调里面就可以拿到文件的内容,如下代码所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
function playMusic () { if (!this.value) { return; } let fileReader = new FileReader(); let file = this.files[0]; fileReader.onload = function () { let arrayBuffer = this.result; console.log(arrayBuffer); } fileReader.readAsArrayBuffer(this.files[0]); } |
这里使用一个FileReader读取文件,读取为ArrayBuffer即原始的二进制内容,把它打印如下所示:
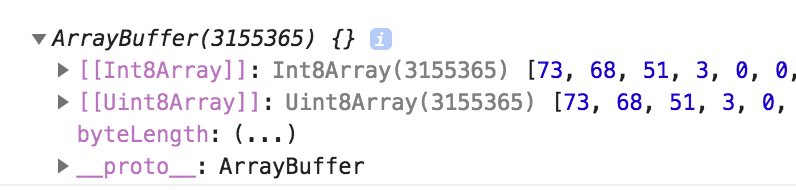
可以用这个ArrayBuffer实例化一个Uint8Array就能读取它里面的内容,Uint8Array数组里面的每个元素都是一个无符号整型8位数字,即0 ~ 255,相当于每1个字节的0101内容就读取为一个整数。更多讨论可以见这篇《前端本地文件操作与上传》。
这个arrayBuffer可以转成一个blob,然后用这个blob生成一个url,如下代码所示:
|
1 2 3 4 5 6 7 8 9 10 |
fileReader.onload = function () { let arrayBuffer = this.result; // 转成一个blob let blob = new Blob([new Int8Array(this.result)]); // 生成一个本地的blob url let blobUrl = URL.createObjectURL(blob); console.log(blobUrl); // 给audio标签的src属性 document.querySelector('.audio-node').src = blobUrl; } |
主要利用URL.createObjectURL这个API生成一个blob的url,这个url打印出来是这样的:
blob:null/c2df9f4d-a19d-4016-9fb6-b4899bac630d
然后丢给audio标签就能播放了,作用相当于一个远程的http的url.
在使用ArrayBuffer生成blob对象的时候可以指定文件类型或者叫mime类型,如下代码所示:
|
1 2 3 |
let blob = new Blob([new Int8Array(this.result)], { type: 'audio/mp3' // files[0].type }); |
这个mime可以通过file input的files[0].type得到,而files[0]是一个File实例,File有mime类型,而Blob也有,因为File是继承于Blob的,两者是同根的。所以在上面实现代码里面其实不需要读取为ArrayBuffer然后再封装成一个Blob,直接使用File就行了,如下代码所示:
|
1 2 3 4 5 6 7 8 |
function playMusic () { if (!this.value) { return; } // 直接使用File对象生成blob url let blobUrl = URL.createObjectURL(this.files[0]); document.querySelector('.audio-node').src = blobUrl; } |
而使用AudioContext需要拿到文件的内容,然后手动进行音频解码才能播放。
2. AudioContext的模型
使用AudioContext怎么播放声音呢,我们来分析一下它的模型,如下图所示:
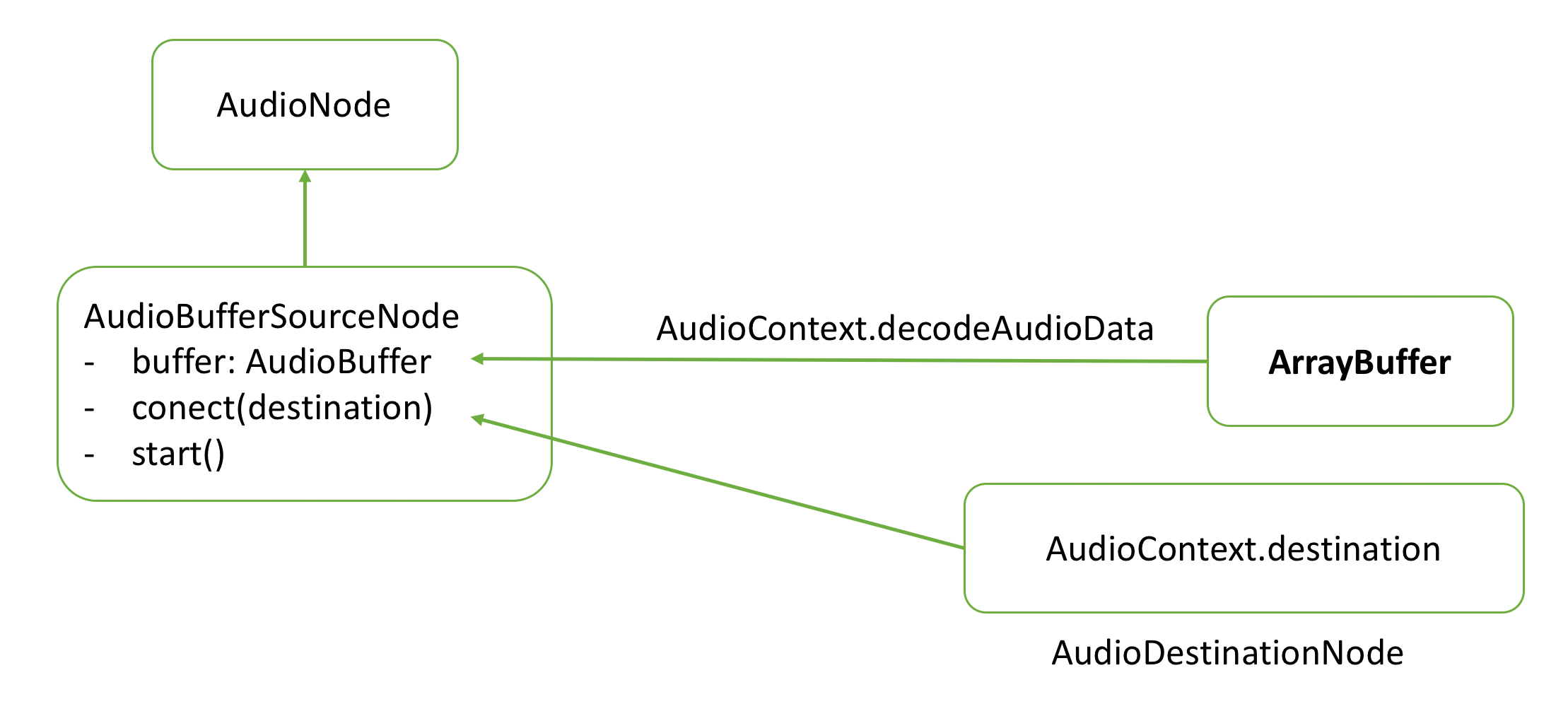
我们拿到一个ArrayBuffer之后,使用AudioContext的decodeAudioData进行解码,生成一个AudioBuffer实例,把它做为AudioBufferSourceNode对象的buffer属性,这个Node继承于AudioNode,它还有connect和start两个方法,start是开始播放,而在开始播放之前,需要调一下connect,把这个Node连结到audioContext.destination即扬声器设备。代码如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
function play (arrayBuffer) { // Safari需要使用webkit前缀 let AudioContext = window.AudioContext || window.webkitAudioContext, audioContext = new AudioContext(); // 创建一个AudioBufferSourceNode对象,使用AudioContext的工厂函数创建 let audioNode = audioContext.createBufferSource(); // 解码音频,可以使用Promise,但是较老的Safari需要使用回调 audioContext.decodeAudioData(arrayBuffer, function (audioBuffer) { console.log(audioBuffer); audioNode.buffer = audioBuffer; audioNode.connect(audioContext.destination); // 从0s开始播放 audioNode.start(0); }); } fileReader.onload = function () { let arrayBuffer = this.result; play(arrayBuffer); } |
把解码后的audioBuffer打印出来,如下图所示:
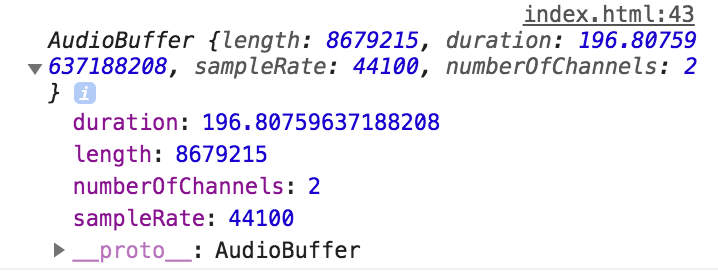
他有几个对开发人员可见的属性,包括音频时长,声道数量和采样率。从打印的结果可以知道播放的音频是2声道,采样率为44.1k Hz,时长为196.8s。关于声音这些属性的意义可见《从Chrome源码看audio/video流媒体实现一》.
从上面的代码可以看到,利用AudioContext处理声音有一个很重要的枢纽元素AudioNode,上面使用的是AudioBufferSourceNode,它的数据来源于一个解码好的完整的buffer。其它继承于AudioNode的还有GainNode:用于设置音量、BiquadFilterNode:用于滤波、ScriptProcessorNode:提供了一个onaudioprocess的回调让你分析处理音频数据、MediaStreamAudioSourceNode:用于连接麦克风设备,等等。这些结点可以用装饰者模式,一层层connect,如上面代码使用到的bufferSourceNode可以先connect到gainNode,再由gainNode connect到扬声器,就能调整音量了。
如下图示意:
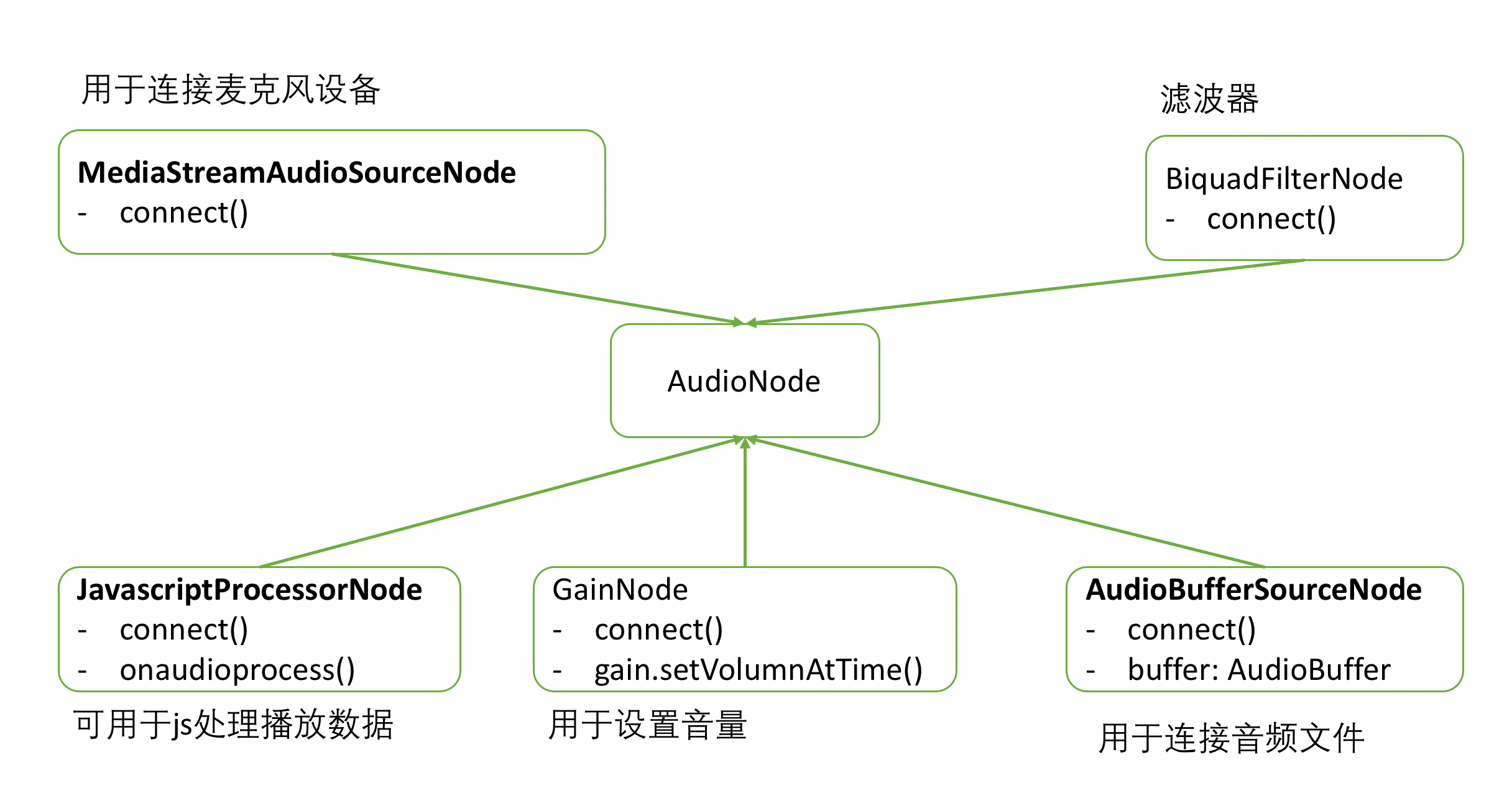
这些节点都是使用audioContext的工厂函数创建的,如调createGainNode就可以创建一个gainNode.
说了这么多就是为了录音做准备,录音需要用到ScriptProcessorNode.
3. 录音的实现
上面播放音乐的来源是本地音频文件,而录音的来源是麦克风,为了能够获取调起麦克风并获取数据,需要使用WebRTC的getUserMedia,如下代码所示;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<button onclick="record()">开始录音</button> <script> function record () { window.navigator.mediaDevices.getUserMedia({ audio: true }).then(mediaStream => { console.log(mediaStream); beginRecord(mediaStream); }).catch(err => { // 如果用户电脑没有麦克风设备或者用户拒绝了,或者连接出问题了等 // 这里都会抛异常,并且通过err.name可以知道是哪种类型的错误 console.error(err); }) ; } </script> |
在调用getUserMedia的时候指定需要录制音频,如果同时需要录制视频那么再加一个video: true就可以了,也可以指定录制的格式:
|
1 2 3 4 5 6 7 8 9 |
window.navigator.mediaDevices.getUserMedia({ audio: { sampleRate: 44100, // 采样率 channelCount: 2, // 声道 volume: 1.0 // 音量 } }).then(mediaStream => { console.log(mediaStream); }); |
调用的时候,浏览器会弹一个框,询问用户是否允许使用用麦克风:
如果用户点了拒绝,那么会抛异常,在catch里面可以捕获到,而如果一切顺序的话,将会返回一个MediaStream对象:

它是音频流的抽象,把这个流用来初始化一个MediaStreamAudioSourceNode对象,然后把这个节点connect连接到一个JavascriptProcessorNode,在它的onaudioprocess里面获取到音频数据,然后保存起来,就得到录音的数据。
如果想直接把录的音直接播放出来的话,那么只要把它connect到扬声器就行了,如下代码所示:
|
1 2 3 4 5 6 |
function beginRecord (mediaStream) { let audioContext = new (window.AudioContext || window.webkitAudioContext); let mediaNode = audioContext.createMediaStreamSource(mediaStream); // 这里connect之后就会自动播放了 mediaNode.connect(audioContext.destination); } |
但一边录一边播的话,如果没用耳机的话容易产生回音,这里不要播放了。
为了获取录到的音的数据,我们把它connect到一个javascriptProcessorNode,为此先创建一个实例:
|
1 2 3 4 5 6 7 8 9 10 |
function createJSNode (audioContext) { const BUFFER_SIZE = 4096; const INPUT_CHANNEL_COUNT = 2; const OUTPUT_CHANNEL_COUNT = 2; // createJavaScriptNode已被废弃 let creator = audioContext.createScriptProcessor || audioContext.createJavaScriptNode; creator = creator.bind(audioContext); return creator(BUFFER_SIZE, INPUT_CHANNEL_COUNT, OUTPUT_CHANNEL_COUNT); } |
这里是使用createScriptProcessor创建的对象,需要传三个参数:一个是缓冲区大小,通常设定为4kB,另外两个是输入和输出频道数量,这里设定为双声道。它里面有两个缓冲区,一个是输入inputBuffer,另一个是输出outputBuffer,它们是AudioBuffer实例。可以在onaudioprocess回调里面获取到inputBuffer的数据,处理之后,然后放到outputBuffer,如下图所示:
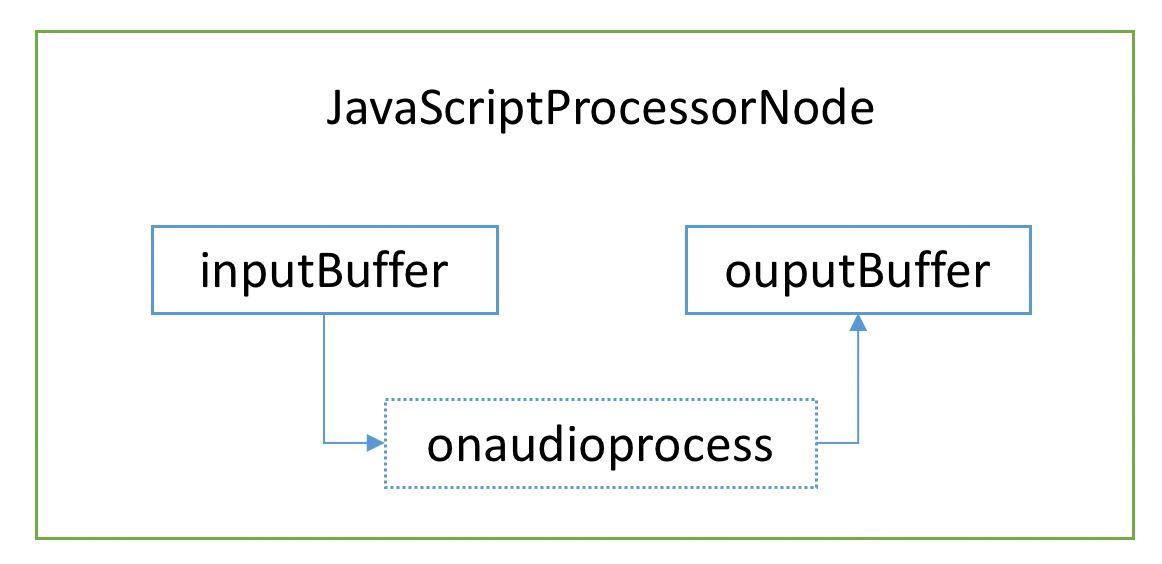
例如我们可以把第1步播放本音频用到的bufferSourceNode连接到jsNode,然后jsNode再连接到扬声器,就能在process回调里面分批处理声音的数据,如降噪。当扬声器把4kB的outputBuffer消费完之后,就会触发process回调。所以process回调是不断触发的。
在录音的例子里,是要把mediaNode连接到这个jsNode,进而拿到录音的数据,把这些数据不断地push到一个数组,直到录音终止了。如下代码所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
function onAudioProcess (event) { console.log(event.inputBuffer); } function beginRecord (mediaStream) { let audioContext = new (window.AudioContext || window.webkitAudioContext); let mediaNode = audioContext.createMediaStreamSource(mediaStream); // 创建一个jsNode let jsNode = createJSNode(audioContext); // 需要连到扬声器消费掉outputBuffer,process回调才能触发 // 并且由于不给outputBuffer设置内容,所以扬声器不会播放出声音 jsNode.connect(audioContext.destination); jsNode.onaudioprocess = onAudioProcess; // 把mediaNode连接到jsNode mediaNode.connect(jsNode); } |
我们把inputBuffer打印出来,可以看到每一段大概是0.09s:
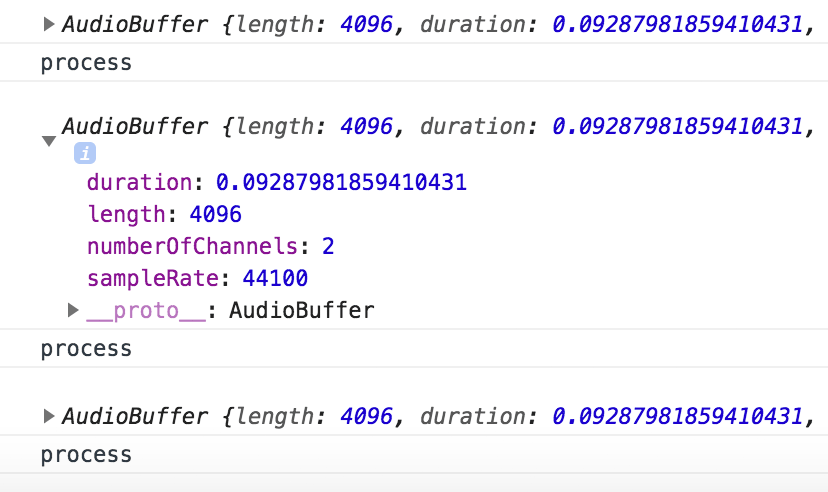
也就是说每隔0.09秒就会触发一次。接下来的工作就是在process回调里面把录音的数据持续地保存起来,如下代码所示,分别获取到左声道和右声道的数据:
|
1 2 3 4 5 6 |
function onAudioProcess (event) { let audioBuffer = event.inputBuffer; let leftChannelData = audioBuffer.getChannelData(0), rightChannelData = audioBuffer.getChannelData(1); console.log(leftChannelData, rightChannelData); } |
打印出来可以看到它是一个Float32Array,即数组里的每个数字都是32位的单精度浮点数,如下图所示:

这里有个问题,录音的数据到底表示的是什么呢,它是采样采来的表示声音的强弱,声波被麦克风转换为不同强度的电流信号,这些数字就代表了信号的强弱。它的取值范围是[-1, 1],表示一个相对比例。
然后不断地push到一个array里面:
|
1 2 3 4 5 6 7 8 9 10 |
let leftDataList = [], rightDataList = []; function onAudioProcess (event) { let audioBuffer = event.inputBuffer; let leftChannelData = audioBuffer.getChannelData(0), rightChannelData = audioBuffer.getChannelData(1); <span class="prism-token token comment"><span data-offset-key="bjk8d-50-0">// 需要克隆一下</span></span><span data-offset-key="bjk8d-51-0"> leftDataList</span><span class="prism-token token punctuation"><span data-offset-key="bjk8d-52-0">.</span></span><span class="prism-token token function"><span data-offset-key="bjk8d-53-0">push</span></span><span class="prism-token token punctuation"><span data-offset-key="bjk8d-54-0">(</span></span><span data-offset-key="bjk8d-55-0">leftChannelData</span><span class="prism-token token punctuation"><span data-offset-key="bjk8d-56-0">.</span></span><span class="prism-token token function"><span data-offset-key="bjk8d-57-0">slice</span></span><span class="prism-token token punctuation"><span data-offset-key="bjk8d-58-0">(</span></span><span class="prism-token token number"><span data-offset-key="bjk8d-59-0">0</span></span><span class="prism-token token punctuation"><span data-offset-key="bjk8d-60-0">)</span></span><span class="prism-token token punctuation"><span data-offset-key="bjk8d-61-0">)</span></span><span class="prism-token token punctuation"><span data-offset-key="bjk8d-62-0">;</span></span><span data-offset-key="bjk8d-63-0"> rightDataList</span><span class="prism-token token punctuation"><span data-offset-key="bjk8d-64-0">.</span></span><span class="prism-token token function"><span data-offset-key="bjk8d-65-0">push</span></span><span class="prism-token token punctuation"><span data-offset-key="bjk8d-66-0">(</span></span><span data-offset-key="bjk8d-67-0">rightChannelData</span><span class="prism-token token punctuation"><span data-offset-key="bjk8d-68-0">.</span></span><span class="prism-token token function"><span data-offset-key="bjk8d-69-0">slice</span></span><span class="prism-token token punctuation"><span data-offset-key="bjk8d-70-0">(</span></span><span class="prism-token token number"><span data-offset-key="bjk8d-71-0">0</span></span><span class="prism-token token punctuation"><span data-offset-key="bjk8d-72-0">)</span></span><span class="prism-token token punctuation"><span data-offset-key="bjk8d-73-0">)</span></span><span class="prism-token token punctuation"><span data-offset-key="bjk8d-74-0">;</span></span> } |
最后加一个停止录音的按钮,并响应操作:
|
1 2 3 4 5 6 7 |
function stopRecord () { // 停止录音 mediaStream.getAudioTracks()[0].stop(); mediaNode.disconnect(); jsNode.disconnect(); console.log(leftDataList, rightDataList); } |
把保存的数据打印出来是这样的:

是一个普通数组里面有很多个Float32Array,接下来它们合成一个单个Float32Array:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
function mergeArray (list) { let length = list.length * list[0].length; let data = new Float32Array(length), offset = 0; for (let i = 0; i < list.length; i++) { data.set(list[i], offset); offset += list[i].length; } return data; } function stopRecord () { // 停止录音 let leftData = mergeArray(leftDataList), rightData = mergeArray(rightDataList); } |
那为什么一开始不直接就弄成一个单个的,因为这种Array不太方便扩容。一开始不知道数组总的长度,因为不确定要录多长,所以等结束录音的时候再合并一下比较方便。
然后把左右声道的数据合并一下,wav格式存储的时候并不是先放左声道再放右声道的,而是一个左声道数据,一个右声道数据交叉放的,如下代码所示:
|
1 2 3 4 5 6 7 8 9 10 11 |
// 交叉合并左右声道的数据 function interleaveLeftAndRight (left, right) { let totalLength = left.length + right.length; let data = new Float32Array(totalLength); for (let i = 0; i < left.length; i++) { let k = i * 2; data[k] = left[i]; data[k + 1] = right[i]; } return data; } |
最后创建一个wav文件,首先写入wav的头部信息,包括设置声道、采样率、位声等,如下代码所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
function createWavFile (audioData) { const WAV_HEAD_SIZE = 44; let buffer = new ArrayBuffer(audioData.length + WAV_HEAD_SIZE), // 需要用一个view来操控buffer view = new DataView(buffer); // 写入wav头部信息 // RIFF chunk descriptor/identifier writeUTFBytes(view, 0, 'RIFF'); // RIFF chunk length view.setUint32(4, 44 + audioData.length * 2, true); // RIFF type writeUTFBytes(view, 8, 'WAVE'); // format chunk identifier // FMT sub-chunk writeUTFBytes(view, 12, 'fmt '); // format chunk length view.setUint32(16, 16, true); // sample format (raw) view.setUint16(20, 1, true); // stereo (2 channels) view.setUint16(22, 2, true); // sample rate view.setUint32(24, 44100, true); // byte rate (sample rate * block align) view.setUint32(28, 44100 * 2, true); // block align (channel count * bytes per sample) view.setUint16(32, 2 * 2, true); // bits per sample view.setUint16(34, 16, true); // data sub-chunk // data chunk identifier writeUTFBytes(view, 36, 'data'); // data chunk length view.setUint32(40, audioData.length * 2, true); } function writeUTFBytes (view, offset, string) { var lng = string.length; for (var i = 0; i < lng; i++) { view.setUint8(offset + i, string.charCodeAt(i)); } } |
接下来写入录音数据,我们准备写入16位位深即用16位二进制表示声音的强弱,16位表示的范围是 [-32768, +32767],最大值是32767即0x7FFF,录音数据的取值范围是[-1, 1],表示相对比例,用这个比例乘以最大值就是实际要存储的值。如下代码所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
function createWavFile (audioData) { // 写入wav头部,代码同上 // 写入PCM数据 let length = audioData.length; let index = 44; let volume = 1; for (let i = 0; i < length; i++) { view.setInt16(index, audioData[i] * (0x7FFF * volume), true); index += 2; } return buffer; } |
最后,再用第1点提到的生成一个本地播放的blob url就能够播放刚刚录的音了,如下代码所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
function playRecord (arrayBuffer) { let blob = new Blob([new Uint8Array(arrayBuffer)]); let blobUrl = URL.createObjectURL(blob); document.querySelector('.audio-node').src = blobUrl; } function stopRecord () { // 停止录音 let leftData = mergeArray(leftDataList), rightData = mergeArray(rightDataList); let allData = interleaveLeftAndRight(leftData, rightData); let wavBuffer = createWavFile(allData); playRecord(wavBuffer); } |
或者是把blob使用FormData进行上传。
整一个录音的实现基本就结束了,代码参考了一个录音库RecordRTC。
4. 小结
回顾一下,整体的流程是这样的:
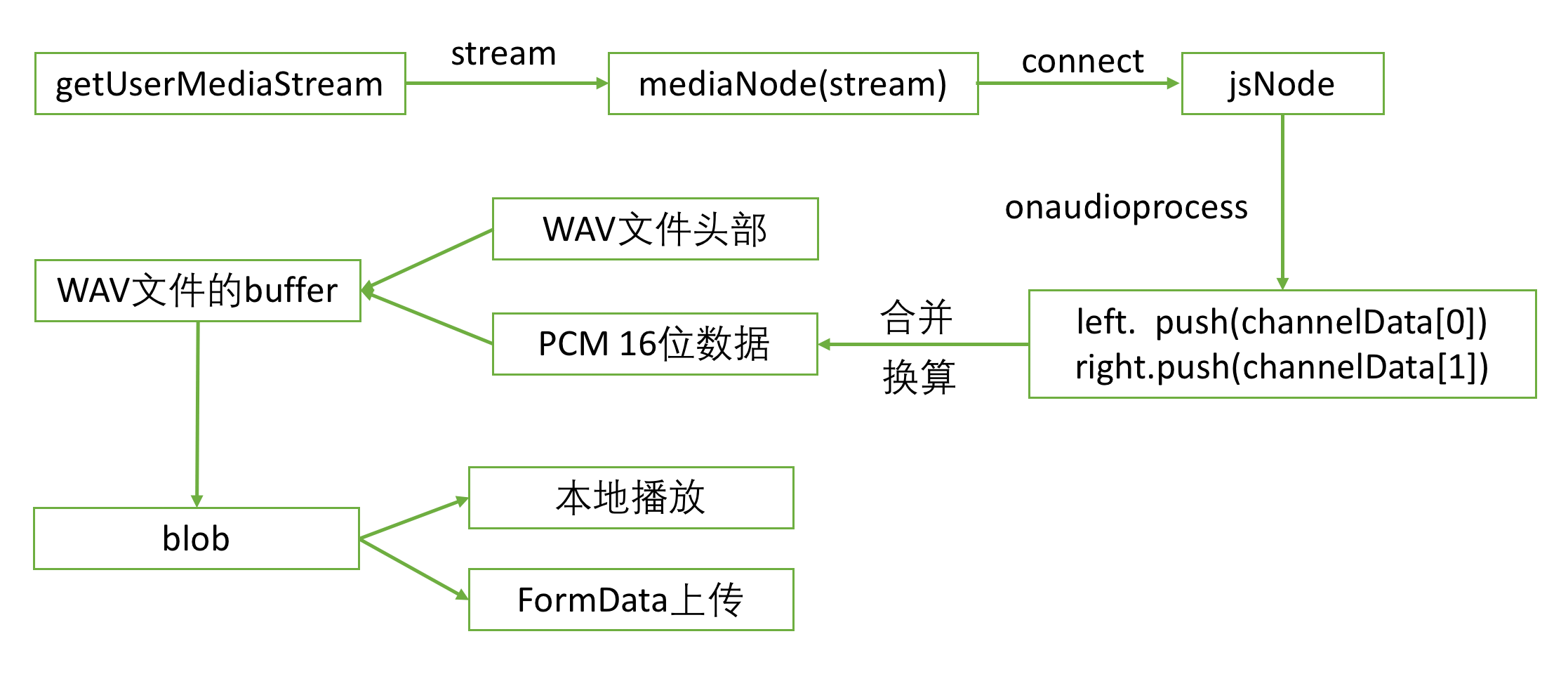
先调用webRTC的getUserMediaStream获取音频流,用这个流初始化一个mediaNode,把它connect连接到一个jsNode,在jsNode的process回调里面不断地获取到录音的数据,停止录音后,把这些数据合并换算成16位的整型数据,并写入wav头部信息生成一个wav音频文件的内存buffer,把这个buffer封装成Blob文件,生成一个url,就能够在本地播放,或者是借助FormData进行上传。这个过程理解了就不是很复杂了。
本篇涉及到了WebRTC和AudioContext的API,重点介绍了AudioContext整体的模型,并且知道了音频数据实际上就是声音强弱的记录,存储的时候通过乘以16位整数的最大值换算成16位位深的表示。同时可利用blob和URL.createObjectURL生成一个本地数据的blob链接。
RecordRTC录音库最后面还使用了webworker进行合并左右声道数据和生成wav文件,可进一步提高效率,避免录音文件太大后面处理的时候卡住了。
然后不断地push到一个array里面:
这个下面的代码有错误