第一篇主要介绍了Chrome加载音视频的缓冲控制机制和编解码基础,本篇将比较深入地介绍解码播放的过程。以Chromium 69版本做研究。
由于Chromium默认不能播放Mp4,所以需要需要改一下源码重新编译一下。
1. 编译一个能播放mp4的Chromium
自行编译出来的Chromium是无法播放mp4视频,在官网下载的也不行,终端会提示这个错误:
[69542:775:0714/132557.522659:ERROR:render_media_log.cc(30)] MediaEvent: PIPELINE_ERROR DEMUXER_ERROR_NO_SUPPORTED_STREAMS
说是在demux即多路解复用的时候发生了错误,不支持当前流格式,也就是Chromium不支持mp4格式的解析,这是为什么呢?经过一番搜索和摸索,发现只要把ffmpeg的编译模式从Chromium改成Chrome就可以。编辑third_party/ffmpeg/ffmpeg_options.gni这个文件,把前面几行代码改一下——把_default_ffmpeg_branding强制设置成Chrome,再重新编译一下就行了,如下代码所示:
|
1 2 3 4 5 |
# if (is_chrome_branded) { _default_ffmpeg_branding = "Chrome" # } else { # _default_ffmpeg_branding = "Chromium" # } |
编译出来的Chromium就能播放视频了。Chromium工程的编译目标branding可以设置成Chrome(正式版)/Chromium/Chrome OS三种模式,ffmpeg的编译设定会根据这个branding类型自动选择它自己的branding,如上代码的判断,如果branding是Chrome,会额外多加一些解码器,就能够播放mp4了。
不过如果你想编译成正式版Chrome,由于缺少相关的主题theme文件,是编译不了的。
另外它还有一个proprietary_codecs的设置:
|
1 |
proprietary_codecs = is_chrome_branded || is_chromecast |
编译正式版的Chrome会默认打开,它的作用是增加一些额外的解码器,如对EME(Encrypted Media Extensions)加密媒体扩展的支持。
最后一开始不能打开和能打开播放的效果对比如下图所示:
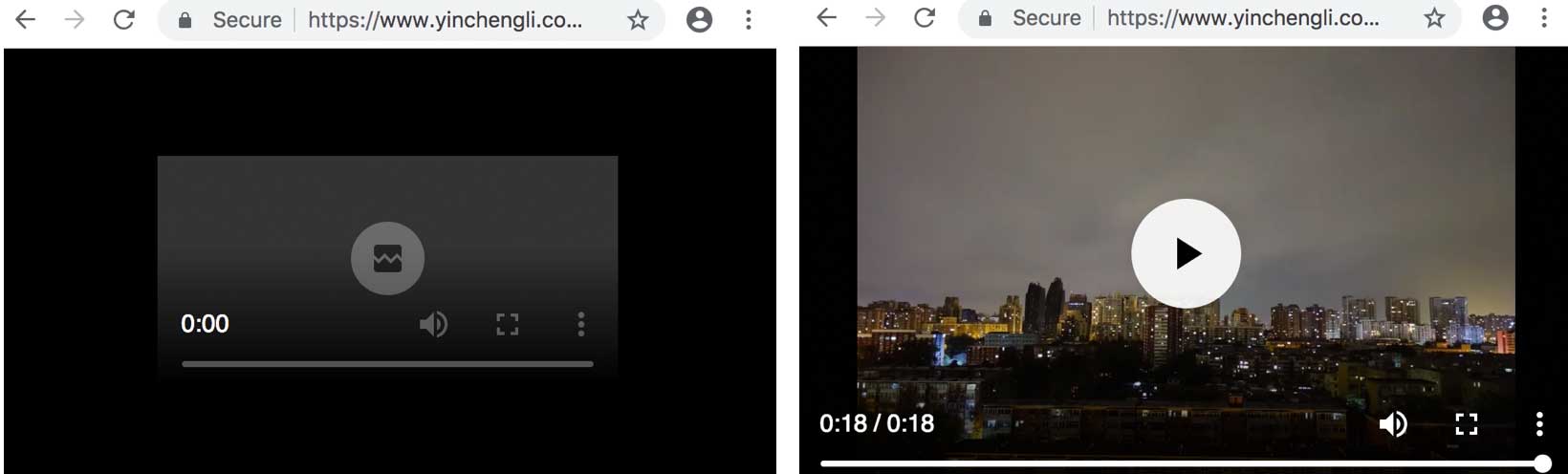
那么为什么Chromium不直接打开mp4支持呢,它可能受到mp4或者ffmpeg的一些开源协议和专利限制。
2. mp4格式和解复用
一个视频可以有3个轨道(Track):视频、音频和文本,但是数据的存储是一维的,从1个字节到第n个字节,那么视频应该放哪里,音频应该放哪里,mp4/avi等格式此做了规定,把视轨音轨合成一个mp4文件的过程就叫多路复用(mux),而把mp4文件里的音视频轨分离出来就叫多路解复用(demux),这两个词是从通信领域来的。
假设现在有个需求,需要取出用户上传视频的第一帧做为封面。这就要求我们去解析mp4文件,并做解码。
我们以这个mountain.mp4时长为1s大小487kB的mp4视频做为研究对象,用sublime等编辑器打开显示其原始的二进制内容,如下图所示:
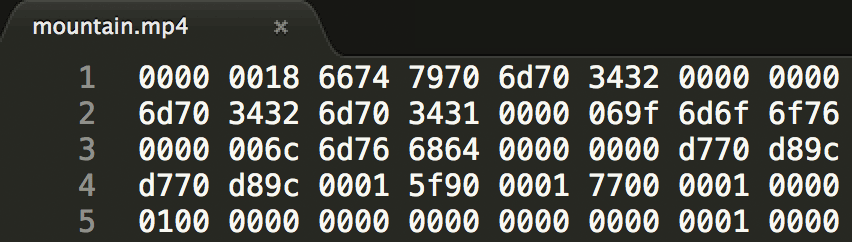
上图是用16进制表示的原始二进制内容,两个16进制(0000)就表示1个字节,如上图第4个字节是0x18。
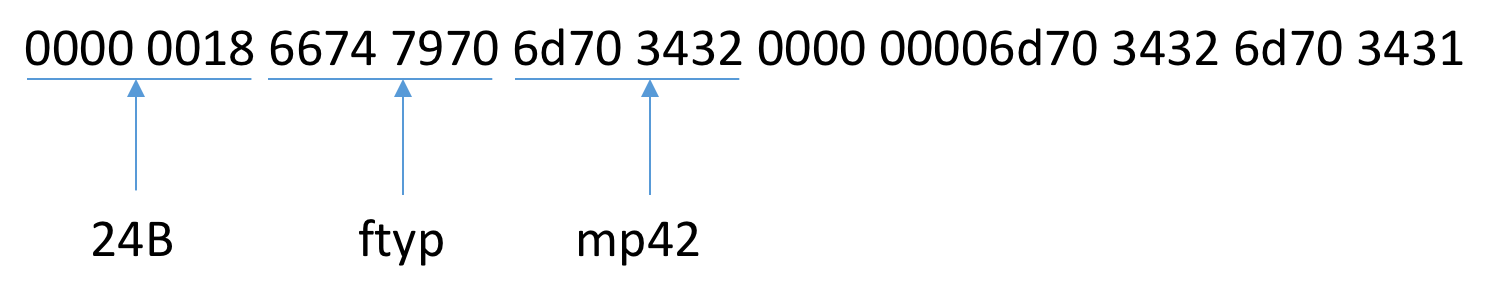
mp4是使用box盒子表示它的数据存储的,标准规定了若干种盒子类型,每种盒子存放的数据类型不一样,box可以嵌套box。每个box的前4个字节表示它占用的空间大小,如上面第一个box是0x18 = 24字节,也就是说在接下来的24字节都是这个box的内容,所以上图到第2行的3431就是第一个box的内容。在前4个表示大小的字节之后紧接着的4个字节是盒子类型,值为ASCII编码,第一个盒子的类型为:
6674 7970 => ftyp
ftyp盒子的作用是用来标志当前文件类型,紧接着的4个字节表示它是一个微软的MPEG-4格式,即平常说的mp4:
6d70 3432 => mp42
综上,第1个盒子整体解析如下图所示:
同样对第二个盒子做分析,如下图所示:
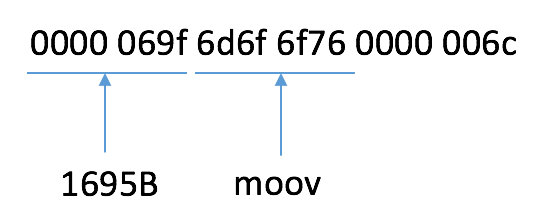
它是一个moov的盒子,moov存储了盒子的metadata信息,包括有多少个音视频轨道,视频宽高是多少,有多少sample(帧),帧数据位于什么位置等等关键信息。注意mp4格式多媒体数据存储可以是不连续的,往后播放的可能反而放在前面,但是没关系。因为这些位置信息都可以从moov这个盒子里面找到。若干个sample组成一个chunk,即一个chunk可以包含1到多个sample,chunk的位置也是在moov盒子里面。
最后面是一个mdat的盒子,这个就是放多媒体数据的盒子,大小为492242B,它占据了mp4文件的绝大部分空间。moov里的chunk的位置偏移offset就是相对于mdat的。
上面我们一个字节一个字节对照着解析比较累,可以用一些现成的工具,如这个在线的MP4Box.js或者是这个MP4Parser,如下图所示,moov里面总共有两个轨道的盒子:
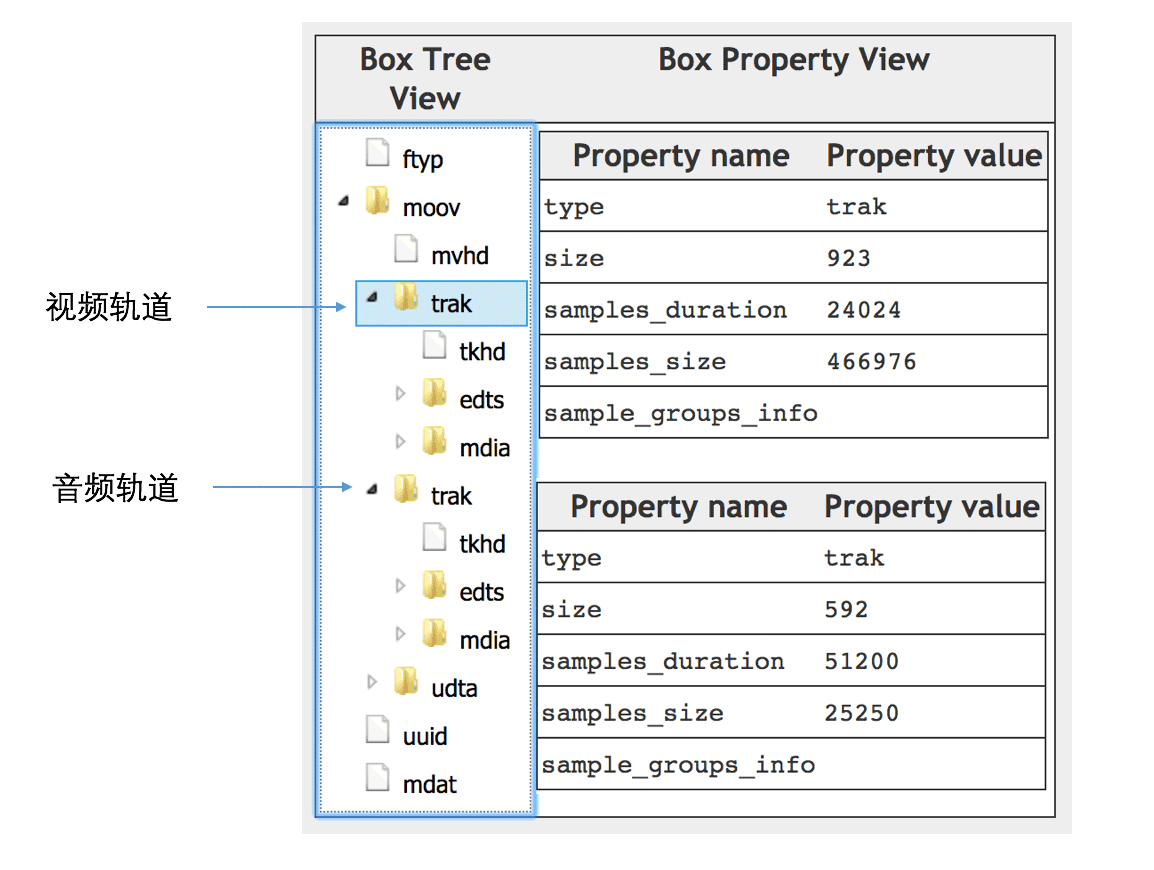
展开视频轨道的子盒子,找到stsz这个盒子,可以看到总共有24帧,每一帧的大小也是可以见到,如下图所示:
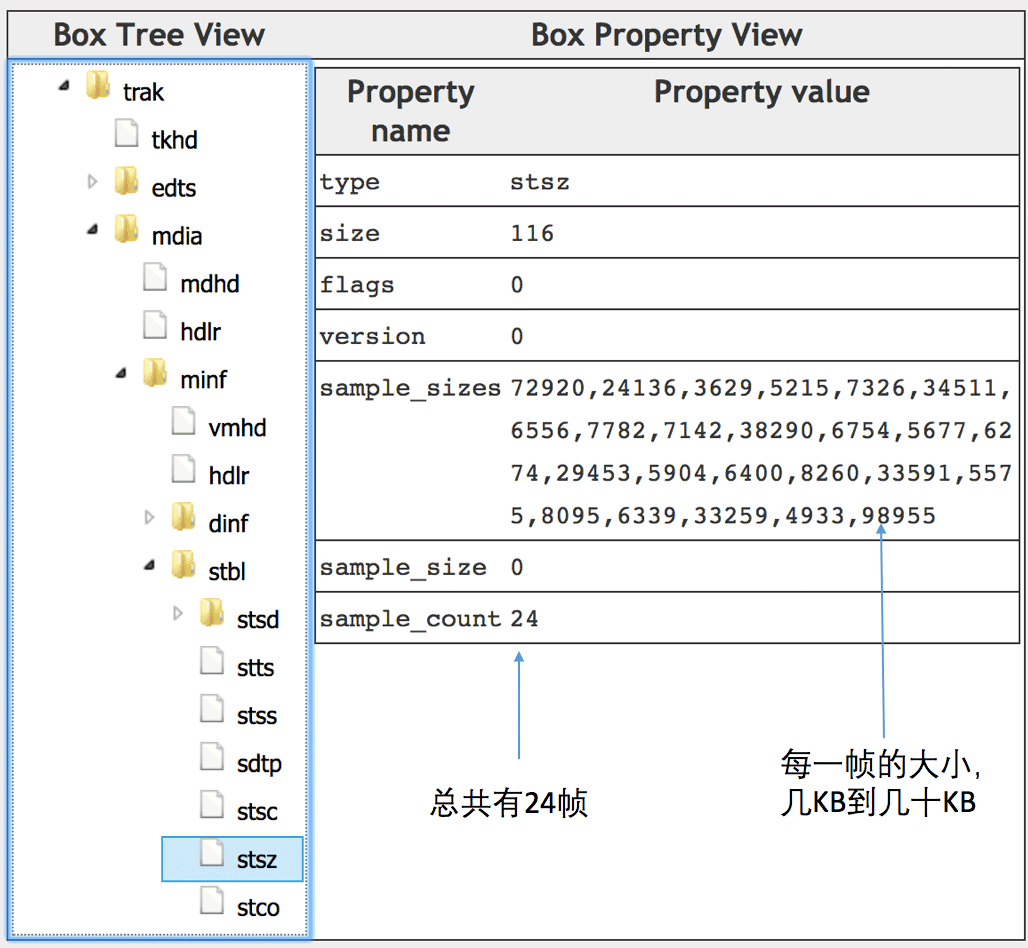
这里我们发现最大的一帧有98KB,最小的一帧只有3KB,一帧就表示一张图像,为什么不同帧差别会这么大呢?
因为有些帧是关键帧(I帧,Intra frame),包含了该帧的完整图象信息,所以比较大,I帧可做为参考帧。另一些帧只是记录和参考帧的差异,叫帧间预测帧(Inter frame),所以比较小,预测帧有前向预测帧P帧和双向预测帧B帧,P帧是参考前面解码过的图像,而B帧参考双向的。所以只是拿到预测帧是没有意义的,需要它前面的那个参考帧才能解码。参考帧(h264)的压缩比类似jpg,一般可达7比1,而预测帧的压缩比可达几十比1。
接着这些帧是怎么存放的呢,它们分别是放在哪些chunk里面的呢,每个chunk的位置又在哪里?如下图stco的盒子所示:
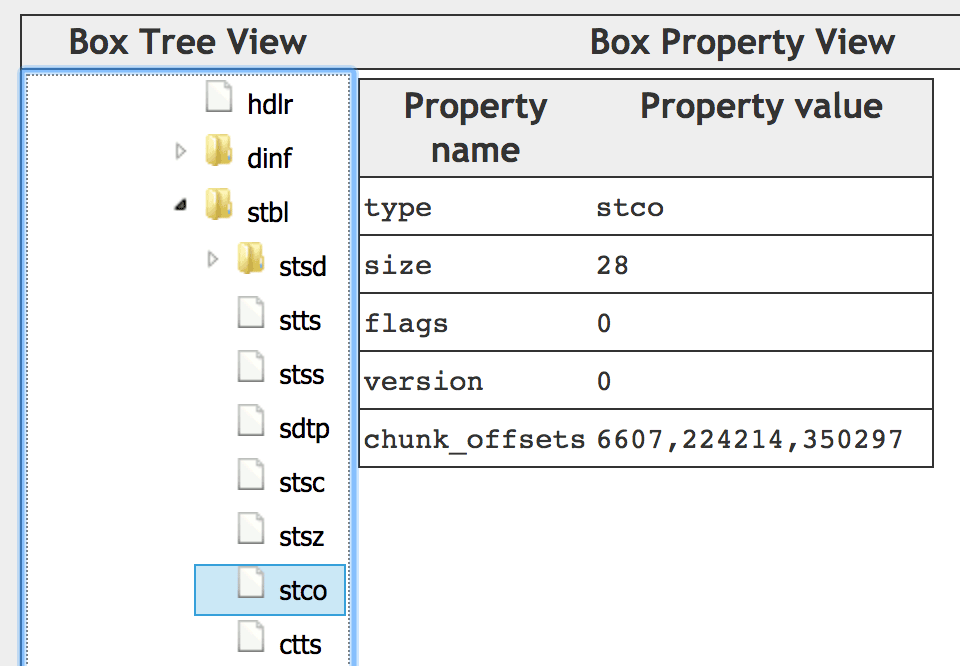
可以看到,总共有3个chunk,每个chunk的位置offsset也都指明。而每个chunk有多少个sample的信息是放在stsc这个盒子里面,如下图所示:
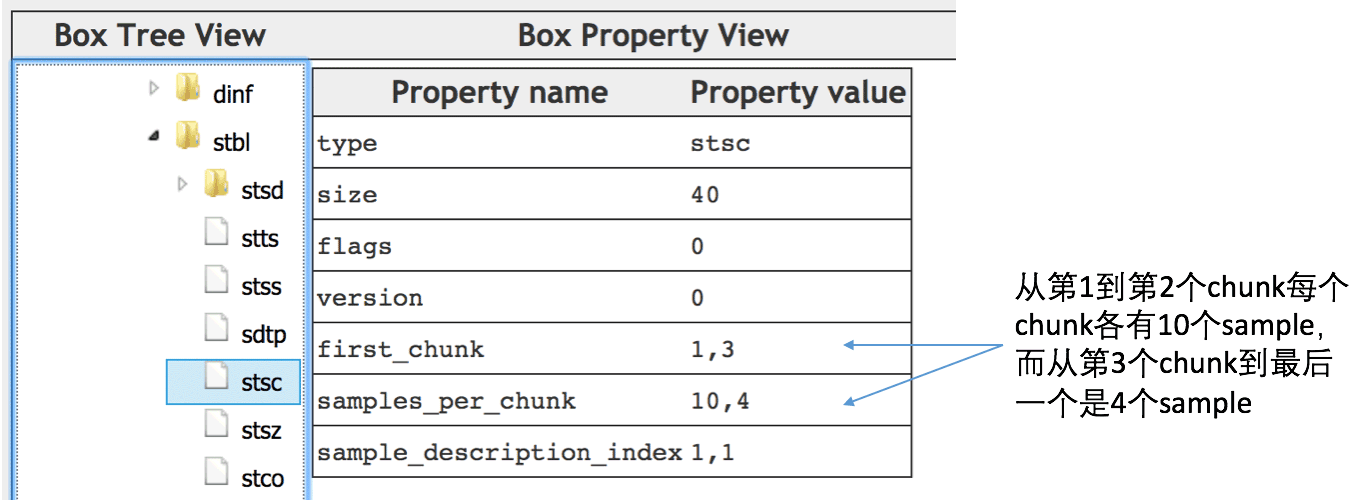
从[1, 3)即第1个到第2个chunk每个chunk有10个sample,而从[3, end)即第3个chunk是4 sample。这样如果我要找第13帧在mdat盒子里的偏移,那么可以知道它是在第2个chunk里的第3个sample,所以参考上面的数据计算起始位置:

而终止位置是236645 + 6274 = 242919,所以第13帧存放在mdat的[236645, 242919)区间。这里有一篇文章介绍了怎么取mp4帧数据的算法,和我们上面分析的过程类似。
这个帧(13帧)这么小,它很可能不是一个关键帧。具体怎么判断它是不是一个关键帧,主要通过帧头部信息里的nal类型,值为5的则为关键帧,这个要涉及到具体的解码过程了。
还有一个问题,怎么知道这个mp4是h264编码,而不是h265之类的,这个通过avc1盒子可以知道,如下图所示:

avc1就是h.264的别名,这个盒子里面放了很多解码需要的参数,如level、SPS、PPS等,如最大参考帧的数目等,参考上图注解。如果最大参考帧放得比较宽,可以使用的参考帧比较多的时候,压缩比能得到提升,但是解码的效率就会降低,并且在seek寻址的时候也不方便,需要往后读很多帧,或者往前保留很多帧,特别是流式播放的时候可能需要提前下载很多内容。上面SPS分析得到的最大参考帧数目是3(max_num_ref_frames).
接下来怎么对图像帧进行解码还原成rgb图像呢?
3. 视频帧解码
I帧的解码不需要参考帧,解码过程比较类似于JPG,P帧和B帧需要依赖前后帧才能还原完整内容,所以帧的解码顺序通常不是按照播放顺序来的。我们不妨研究一下上面的示例视频的所有帧的类型,可以借助一个在线网站Online Video GOP Analyzer,分析结果如下图所示:
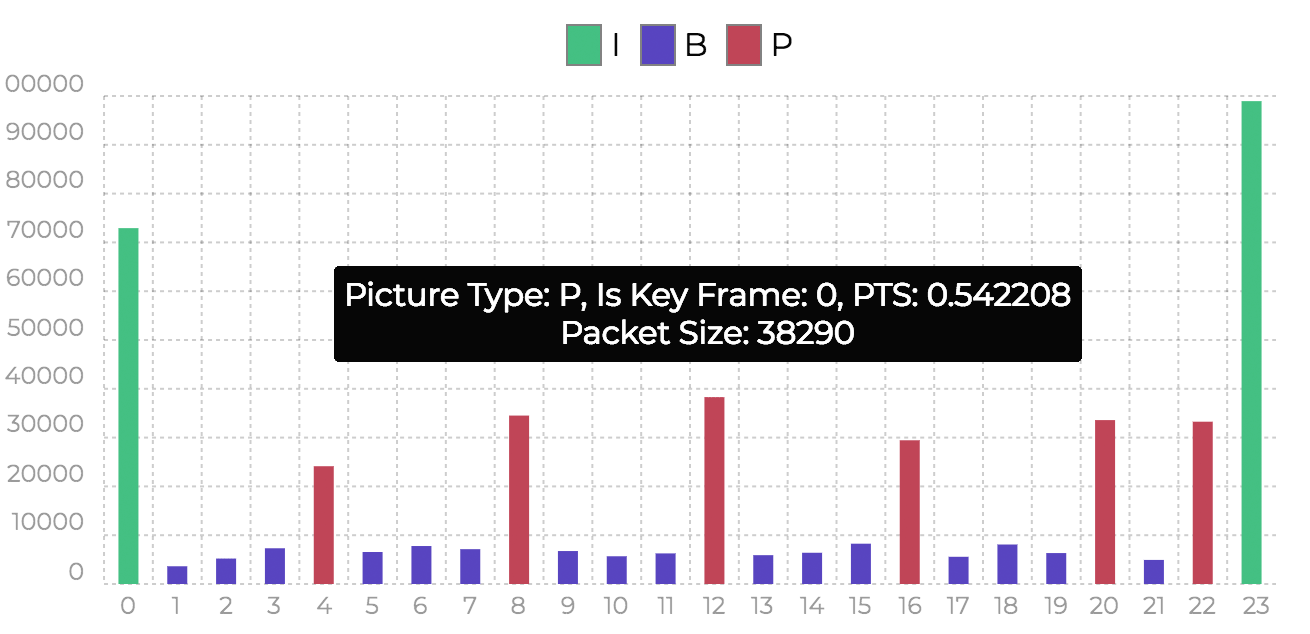
x轴表示从0到23共24帧,y轴表示每一帧的大小,绿色的是关键帧I帧,红色的是前向预测帧P帧,蓝色的表示双向预测帧B帧,可以清楚地看到,在体积上I帧 > P帧 > B帧。这24个帧的排列顺序:
I B B B P B B B P … B P I
首尾两帧都是I帧,刚好形成一个GOP图像序列(group of pictures),在一个GOP序列里面,I帧是起始帧,接下来是B帧和P帧(可能会没有B帧)。
上图的帧顺序是按照每个帧播放时间戳PTS(presentation timestamp)依次递增,其中第12帧(中间红色柱子)推导的播放时间点PTS是0.54s。
但是存储顺序和解码顺序并不是按照播放的顺序来的,可对比第2步里的帧的大小图:
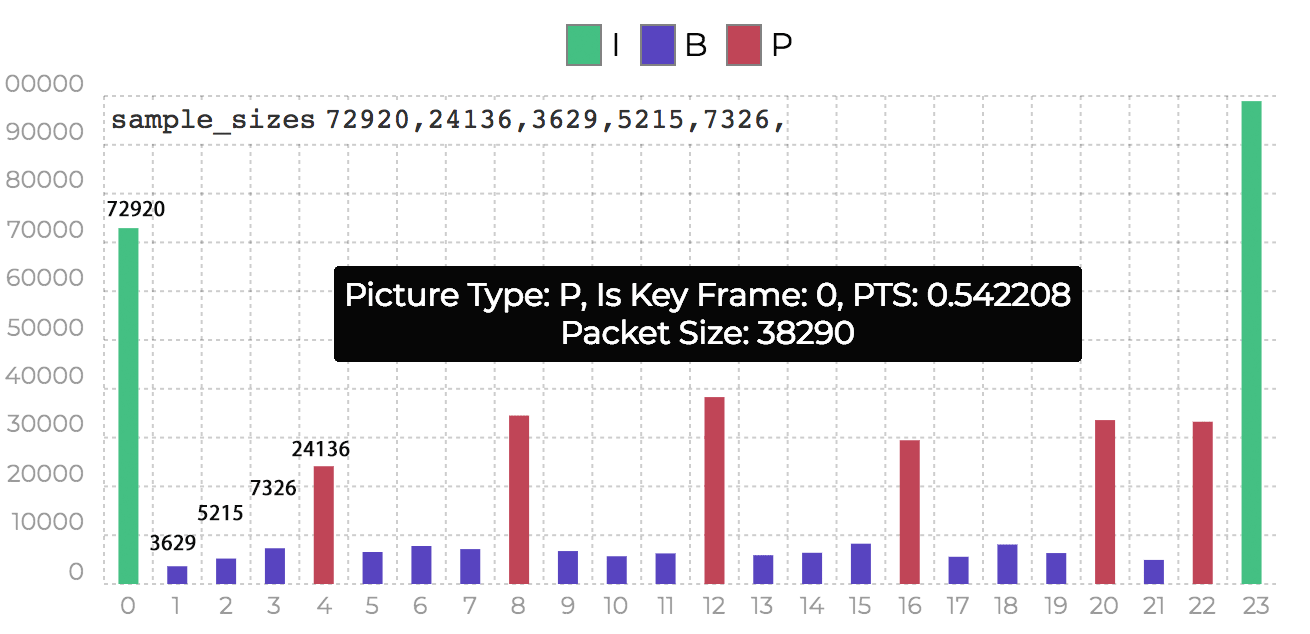
其中,sample_sizes是存储的顺序,柱形图的顺序是按照PST,两者对比可以看到每一帧的解码时间戳DTS(decode timestamp)是按照以下顺序:
I P B B B P B B B …
在一个GOP序列里面,I帧是起始帧,最先解析,然后就是P帧,最后才是B帧,可以猜测因为P帧依赖于I帧,所以要先P帧要先于B帧,而B帧可能要依赖于I帧和P帧,所以最后才能解析。那怎么才能知道具体的依赖关系,也就是每一帧的参考帧列表呢?
首先每一帧的播放顺序POC(Picture Order Count)可以从每一帧的头部信息计算得到,借助一些如JW Reference软件,能够查到从存储顺序的第1帧到第5帧POC依次为:
0 8 2 4 6 …
这里是按照2递增的,换算成1的话就是:
0 4 1 2 3 …
与上面的分析一致。
接着怎么知道帧间预测帧B帧和P帧的参考帧是谁呢?在回答这个问题之前需要知道参考帧参考的是什么,在jpg/h264里面把图片划分为一个个的宏块(macroblock),一个宏块是16 * 16px,以宏块为单位进行存储,记录的颜色信息是以YCbCr格式,Y是指亮度也就是灰度,Cb是指蓝色分量,Cr是红色的分量。如下图所示:

帧间预测帧的宏块只是记录了差值,所以需要找到参考帧列表的相似宏块。由相似宏块和差值还原完整内容。
而参考帧列表是在解码过程中动态维护的,放到一个DPB(decoded picture buffer)的数据结构里面,里面有两个list,list0放的是前向的,list1放的是后向的,依据最大参考帧数目DPB的空间有限,满了之后会有一定的策略清空或者重置。
在参考帧里面找到匹配的宏块就叫运动估计,借助匹配块恢复完整宏块就是运动补偿。如下图所示:
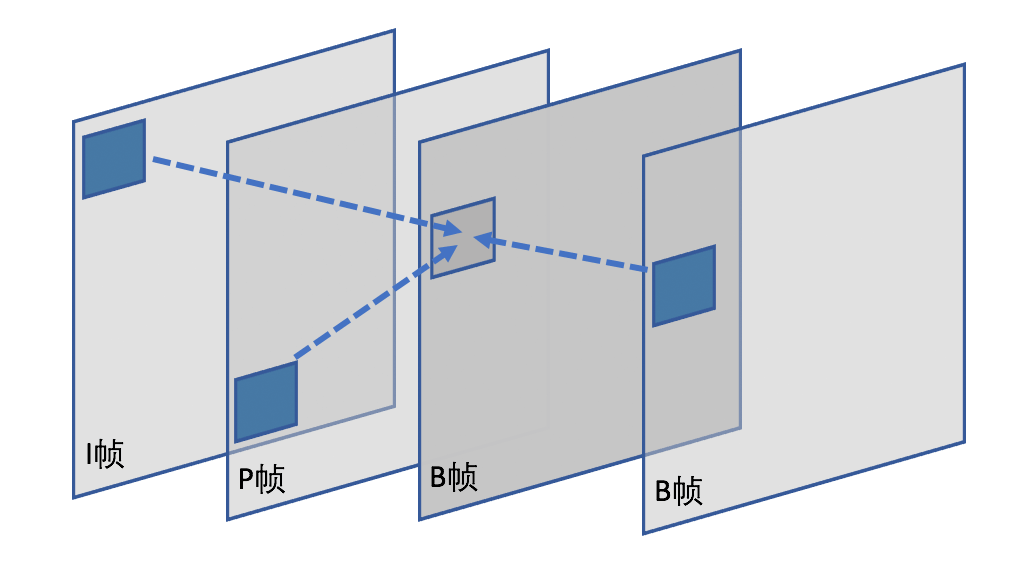
上图第3帧B帧的一个块找到的匹配块有3个,分别是相邻的I、P、B,这3帧就是它的参考帧。箭头方向就是表示运动矢量,通过上图示意,可以知道物体是从上往下运动的(注意上面的顺序是存储顺序IPBB,而播放顺序是IBBP)。
运动估计和运动补偿的算法有多种,h264有推荐的使用算法。
至此我们知道了解码的基本原理,具体怎么把那一帧的图像解码为rgb图片,我在《wasm + ffmpeg实现前端截取视频帧功能》把ffmpeg编译成wasm,然后在前端页实现了这个功能。主要利用ffmpeg的解码,Chrome也是用的ffmpeg做为它的解码引擎。关键调用函数为avcodec_decode_video2(这个已被deprecated,下文会继续提及)。
借助ffmpeg,我们能够把所有的帧解析出来变成rgb图片,这些图片怎么形成一个视频呢?
4. 视频播放
最直观的做法就是根据帧率,如上面的示例视频帧率为25fps,1s有25帧,每一帧播放间隔时长为1s / 25 = 0.04s,即每隔40ms就播放一帧,这样就形成一个视频了。利用ffmpeg的av_frame_get_best_effort_timestamp函数可以得到每一帧的PST播放时间,理论上以开始播放的时间为起点,在相应的时间差播放对应PST的帧就可以了。实现上可以让播放视频的线程sleep相邻两个帧的pst时间差,时间到了线程唤醒后再display显示新的帧。
实际上为了更好地保证音视频同步,需要以当前音频播放的时间做一个修正。例如,如果解码视频的线程卡了跟不上了,和音频的时间audioClock相差太多,超过一个阈值如0.1s那么这一帧就丢掉了,不要展示了,相反如果是解码视频线程快了,那么delay一下,让播放视频的线程休眠更长的时间,保持当前帧不动。更科学的方法是让音频和视频同时以当前播放的时间做修正,即记录一下开始播放的系统时间,用当前系统时间减掉开始时间就得到播放时间。Chrome就是这么做的,当我们看Chrome源码的时候会发现这个过程比上面描述得要复杂。
5. Chrome视频播放过程
我们从多路解复用开始说起,Chrome的多路解复用是在src/media/filters/ffmpeg_demuxer.cc里面进行的,先借助buffer数据初始化一个format_context,记录视频格式信息,然后调avformat_find_stream_info得到所有的streams,一个stream包含一个轨道,循环streams,根据codec_id区分audio、video、text三种轨道,记录每种轨道的数量,设置播放时长duration,用fist_pts初始化播放开始时间start_time。并实例化一个DemuxerStream对象,这个对象会记录视频宽高、是否有旋转角度等,初始化audio_config和video_config,给解码的时候使用。这里面的每一步几乎都是通过PostTask进行的,即把函数当作一个任务抛给media线程处理,同时传递一个处理完成的回调函数。如果其中有一步挂了就不会进行下一步,例如遇到不支持的容器格式,在第一步初始化就会失败,就不会调回调函数往下走了。
解码是使用ffmpeg的avcodec_send_packet和avcodec_receive_frame进行的音视频解码,上文提到的avcodec_decode_video2已经被弃用,ffmpeg3起引入了新的解码函数。
解码和解复用都是在media线程处理的,如下图所示:
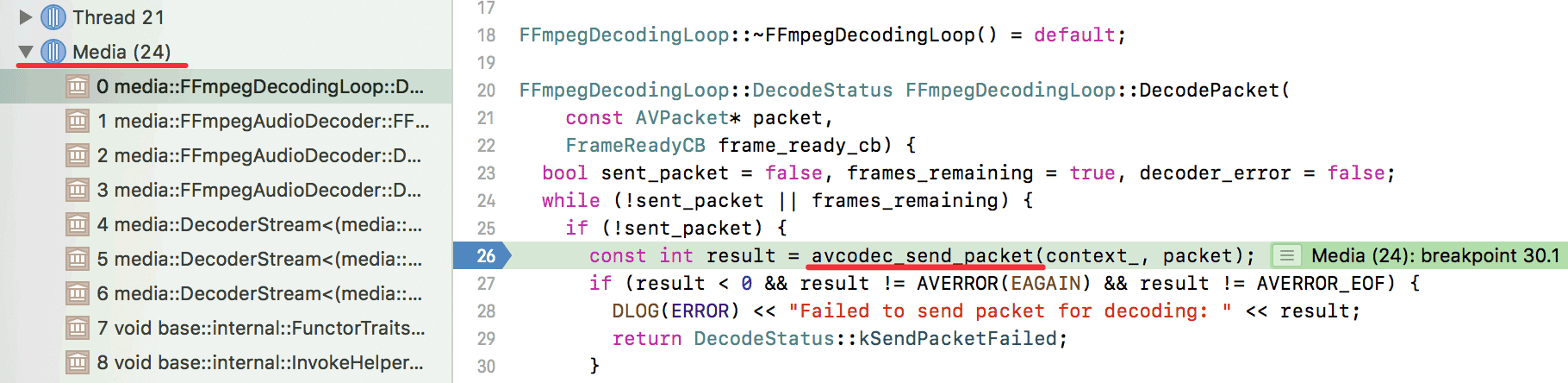
音频解码完成会放到audio_buffer_renderer_algorithm的AudioBufferQueue里面,等待AudioOutputDevice线程读取。为什么起名叫algorithm,因为它还有一个作用就是实现WSOLA语音时长调整算法,即所谓的变速不变调,因为在JS里面我们是可以设置audio/video的playback调整播放速度。
视频解码完成会放到video_buffer_renderer_algorithm.cc的buffer队列里面,这个类的作用也是为了保证流畅的播放体验,包括上面讨论的时钟同步的关系。
准备渲染的时候会先给video_frame_compositor.cc,这个在media里的合成器充当media和Chrome Compositor(最终合成)的一个中介,由它把处理好的frame给最终合成并渲染,之前的文章已经提过Chrome是使用skia做为渲染库,主要通过它提供的Cavans类操作绘图。
Chrome使用的ffmpeg是有所删减的,支持的格式有限,不然的话光是ffmpeg就要10多个MB了。
以上就是整体的过程,具体的细节如怎么做音视频同步等,本篇没有深入去研究。
7. 小结
本篇介绍了很多了视频解码的概念,包括mp4容器的格式特点,怎么进行多路解复用取出音视频数据,什么是I帧、B帧和P帧。介绍了在解码过程中播放时间PST和解码顺序DST往往是不一致的(如果有B帧),B帧和P帧通过运动估计、运动补偿进行解码还原。最后介绍Chrome是怎么利用ffmpeg进行解码,分析了Chrome播放视频的整体过程。
阅读完本篇内容并不能成为一个多媒体高手,但是可以对多媒体的很多概念有一个基本了解,当你去参加一些多媒体技术会议的时候就不会听得雾里云里的。本篇把很多多媒体基础串了起来,这也是我研究了很久才得到的一些认知,我的感受是多媒体领域的水很深,需要有耐心扎进去才能有所成,但多媒体又是提高生活质量的一个很重要的媒介。

受益非浅,非常适合入门的tutorial,感谢作者的辛勤付出
很赞~ 请教个问题,在解码的时候,请问如何找到参考帧呢?我在帧头里面并没有找到某个帧的参考帧序号。如楼主所述,帧间预测帧的宏块只是记录了差值,如果要解码,需要知道它的参考宏块才对(以及有一个索引值),这些信息是如何记录下来的呢?
往前找最近的
很强
您好,很高兴能看见您关于这方面的研究。wasm应用于前端转码您说的“并且WebAssembly.Memory只能grow,不能shrink”,这个是主要障碍吗,其他问题我看都可以通过优化的方式来解决,目前前端使用webassmely解码有公司在使用吗?感谢您能给回复